
Autoregressive-to-Diffusion Vision Language Models
Efficient training of state-of-the-art diffusion vision language models.
September 24, 2025
by Marianne Arriola *, Naveen Venkat †, Jonathan Granskog, Anastasis Germanidis
We develop a state-of-the-art diffusion vision language model, Autoregressive-to-Diffusion (A2D), by adapting an existing autoregressive vision language model for parallel diffusion decoding. Our approach makes it easy to unlock the speed-quality trade-off of diffusion language models without training from scratch, by leveraging existing pretrained autoregressive models.

1x parallel: slow

2x parallel: faster, with comparable quality

3x parallel: much faster, with quality degradation

Fig 1: Diffusion VLMs offer a trade-off between quality and speed by tuning the amount of generation steps. Under fewer generation steps, we achieve higher parallelism (number of concurrent tokens, averaged over the sequence). Diffusion decoding also supports error correction, where low-confidence tokens (red tokens) are revoked and replaced (green tokens).
Vision language models (VLMs) reason about images and videos through language, powering applications from image captioning to visual question answering. Autoregressive VLMs generate tokens sequentially, which prevents parallelization and limits inference throughput. Diffusion decoders are emerging as a promising alternative to autoregressive decoders in VLMs by enabling parallel token generation for faster inference. [1, 2, 3]
Whereas autoregressive language models are limited to a fixed inference throughput, diffusion language models can use fewer generation steps for higher throughput at the cost of quality. As a result, diffusion language models present a flexible trade-off between speed and quality.
The key to managing the speed-quality trade-off is a confidence threshold that adaptively controls parallelism [9]. When the confidence threshold is set high (e.g., 90%), the model prioritizes accuracy, generating multiple tokens only when highly certain. When the threshold is set lower (e.g., 30%), it prioritizes speed, tolerating more ambiguity to achieve greater parallelism.
Whereas autoregressive language models are limited to a fixed inference throughput, diffusion language models can use fewer generation steps for higher throughput at the cost of quality. As a result, diffusion language models present a flexible trade-off between speed and quality.
The key to managing the speed-quality trade-off is a confidence threshold that adaptively controls parallelism [9]. When the confidence threshold is set high (e.g., 90%), the model prioritizes accuracy, generating multiple tokens only when highly certain. When the threshold is set lower (e.g., 30%), it prioritizes speed, tolerating more ambiguity to achieve greater parallelism.
Existing diffusion VLMs face practical challenges:
Expensive to train. Current diffusion VLMs finetune diffusion LLMs [4, 5] to integrate visual features. However, diffusion language modeling requires up to 16x more training compute than next-token prediction [6]. For example, diffusion VLM LLaDA-V 8B [1] requires training on ≥12M visual QA pairs.
Outdated architectures: Current diffusion VLMs lack modern architectural components compared to recent autoregressive VLMs such as the Qwen2.5-VL series [7], which offer support for native visual resolutions, multimodal positional encodings, and dynamic FPS sampling.
Quality degradation in long-form responses: We observe that sample quality degrades for longer outputs (e.g., chain-of-thought reasoning and detailed image captioning). Existing models [1, 2] perform diffusion over the full sequence at once during training and inference, which has been shown to degrade quality [4, 8]. In contrast, decoding in smaller blocks of tokens (e.g., 8 tokens at a time) inference improves quality and generalization to arbitrary-length responses. [8]
Lack of KV caching. Existing diffusion VLMs utilize bidirectional attention during training, which hinders KV (key-value) caching for efficient attention computation [8]. While LLaDA-V 8B may cache and periodically update KVs throughout inference, it is an approximate caching mechanism that requires expensive recomputation.
We adapt powerful pretrained VLMs for parallel diffusion decoding
We present a novel diffusion VLM, A2D-VL 7B (Autoregressive-to-Diffusion) for parallel generation by finetuning an existing autoregressive VLM, Qwen2.5-VL [7], on the diffusion language modeling task [8]. In particular, we adopt the masked diffusion framework [10, 11, 12] which "noises" tokens by masking them and "denoises" tokens by predicting the original tokens. We propose novel adaptation techniques (Fig. 2) that gradually increase the task difficulty during finetuning to smoothly transition from sequential to parallel decoding while preserving the base model's capabilities.
Fig 2: Our proposed diffusion vision language model, Autoregressive-to-Diffusion VLM (A2D-VL). We adapt pretrained autoregressive VLMs for parallel diffusion decoding by progressively increasing the length of the prediction window.
Further, we present novel adaptation techniques for finetuning autoregressive models into diffusion models while retaining the base model's core capabilities:
Block size annealing. The block diffusion framework enables interpolation between autoregressive and diffusion modeling: when blocks contain single tokens, we recover sequential decoding. We leverage this by gradually increasing the diffusion prediction window throughout finetuning, starting from smaller blocks and progressing to our target size of 8 tokens. This gradual progression prevents the aggressive parameter updates that would otherwise erase the base model's capabilities.
Noise level annealing. Within each token block, we apply position-dependent masking to gradually transition from easier to harder prediction tasks. Early in training, we mask the left-most tokens closest to the context more frequently (since they're easier to predict) and right-most tokens less frequently (since they're harder to predict). As training progresses, masking becomes uniform across positions, enabling any-order parallel generation within each block.
We ablate these strategies in Fig. 3, which shows the importance of both strategies for preserving benchmark performance of the base model. Concurrently, [14] also adapts Qwen2.5 for block diffusion decoding in NLP-only tasks. In contrast, we explore vision language models and propose novel adaptation techniques that are critical for retaining model capabilities.
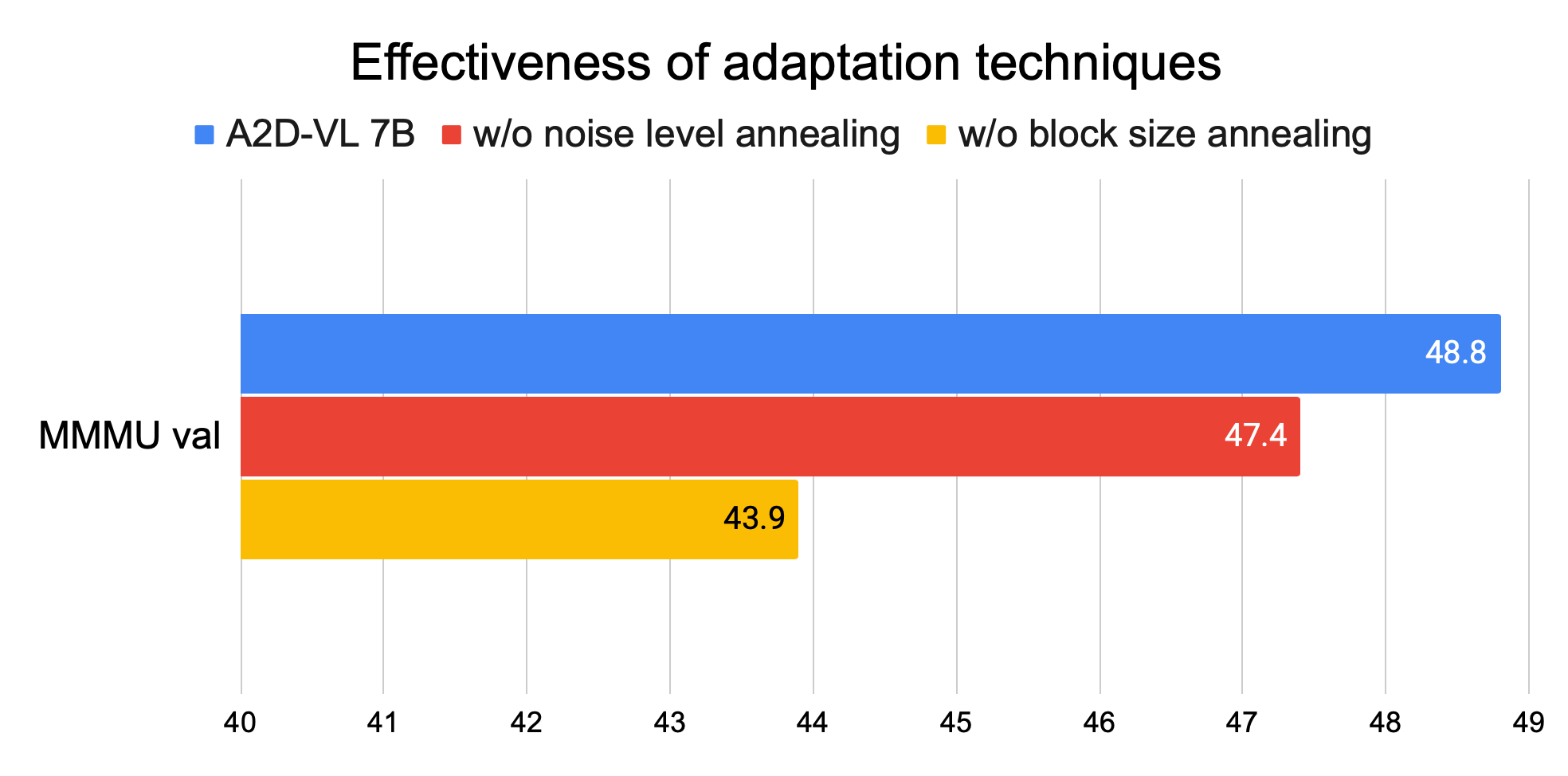
Fig 3: Ablation on proposed adaptation techniques from finetuning Qwen2.5 VL 7B on 50K examples.
Our design overcomes the limitations of prior diffusion VLMs:
Efficient training. By adapting existing VLMs, our approach requires significantly less training than training diffusion VLMs from scratch. While LLaDA-V 8B [1] trains on ≥12M visual QA pairs, our A2D-VL 7B is trained on 400K pairs.
Modern architecture. By adapting Qwen2.5-VL, we adopt their modern architectural components, such as support for native visual resolutions and multimodal positional encodings.
Improved quality in long-form responses. We use diffusion decoding in blocks of 8 tokens, which enhances both response quality and the model's ability to generate arbitrary-length outputs [8]. Further, our training data contains 100K high-quality reasoning traces from the larger Qwen2.5-VL 72B while [1, 2] rely on standard instruction-tuning data, with [2] also distilling from a 7B math/science reasoning model. To enhance response flexibility, we also include 50K samples from MAmmoTH-VL [13] in our data mixture similar to [1].
KV caching support. Under the block diffusion training and inference framework [8], A2D-VL sequentially generates a block of tokens at a time using block-causal attention (attending only to previous blocks and tokens within the current block) rather than fully bidirectional attention as in [1, 2, 3]. As a result, A2D-VL supports exact KV caching of previously generated blocks instead of relying on approximate methods
We strike a new balance between speed and performance
By adapting pretrained autoregressive VLMs for diffusion, A2D-VL strikes an improved balance between inference speed and downstream performance. We compare the speed-quality trade-off between A2D-VL 7B, Qwen2.5-VL 7B, and the diffusion VLM LLaDA-V 7B. For LLaDA-V, we follow the recommended settings: approximate KV caching with recomputation every 32 steps and "factor"-based confidence thresholding [1, 9].
Detailed image captioning: We generate detailed image captions (≤ 512 tokens) and, similarly to [15], score them against captions generated by GPT-4o, GPT-4V, and Gemini-1.5-Pro using BERTScore to measure semantic similarity. Captions generated by A2D-VL achieve greater consistency with the reference captions compared to prior diffusion VLM LLaDA-V.
Chain-of-thought reasoning: A2D-VL consistently achieves better MMMU-Pro accuracy with chain-of-thought prompting compared to LLaDA-V. For Qwen2.5 and A2D-VL, we generate up to 16k tokens. For LLaDA-V, we limit the response to 512 tokens as the accuracy degrades at longer output lengths.
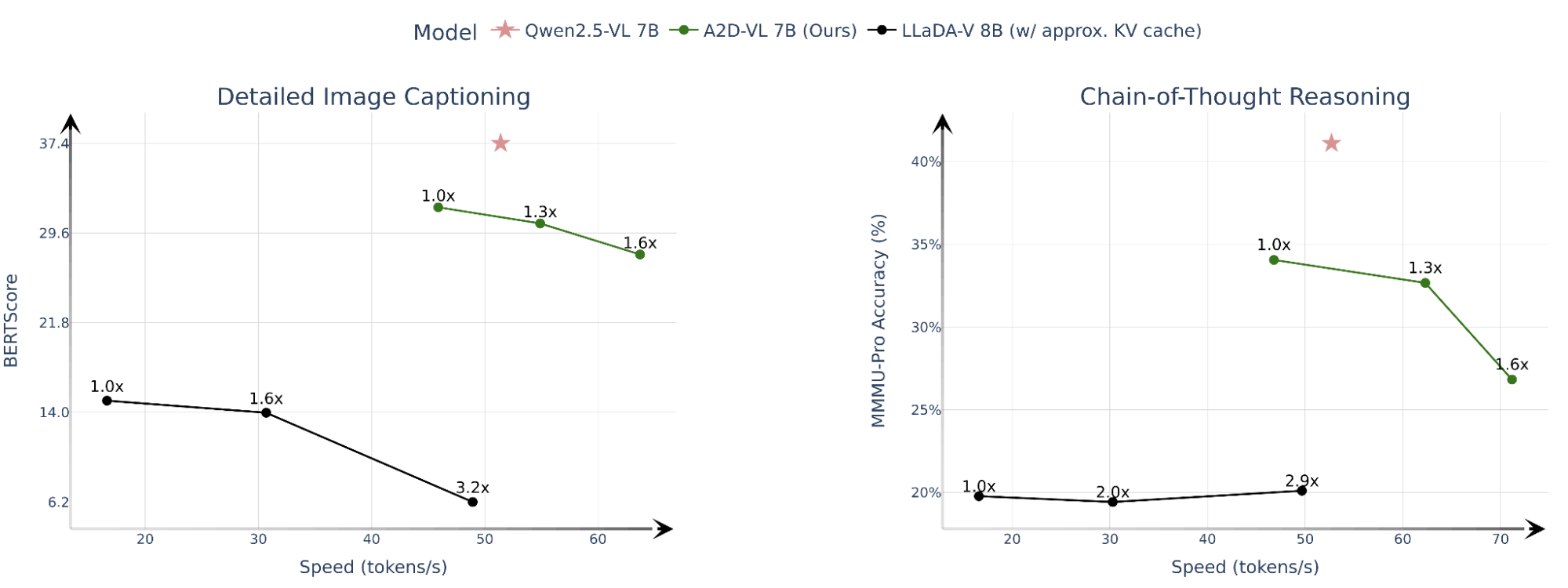
Fig 4: Speed-quality trade-off when tuning the number of generation steps. We indicate the parallelism factor for diffusion VLMs as the number of tokens generated concurrently, averaged across the sequence (i.e. 1x parallelism refers to single-token sampling). Throughputs are measured on 8xH100s, reported as per-device averages.
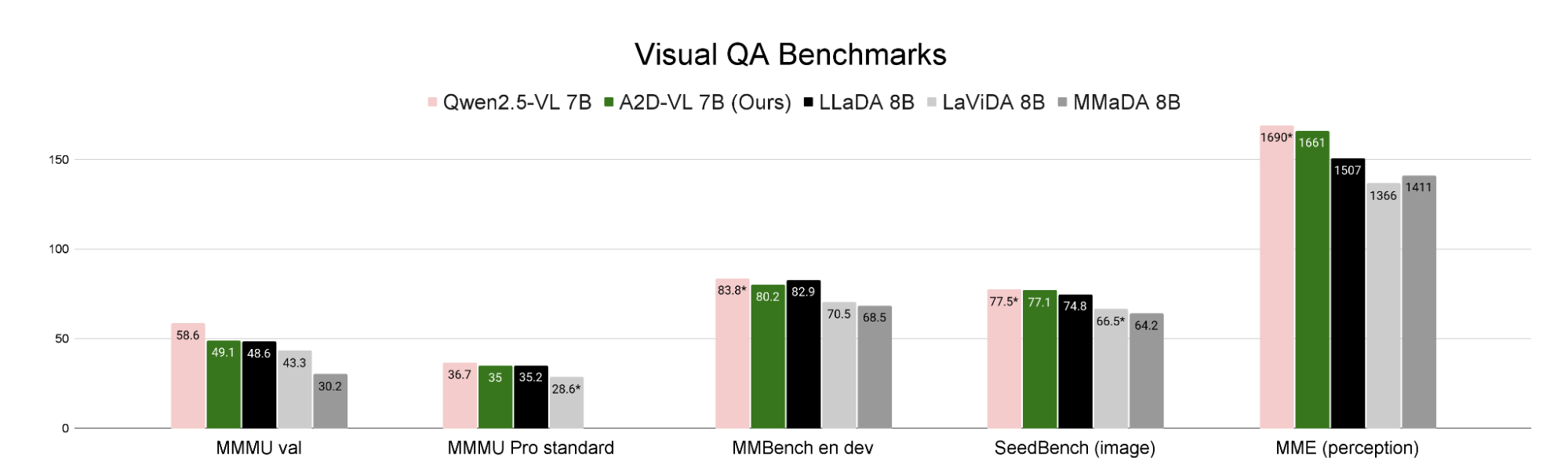
Fig 5: Performance on multiple-choice visual question-answering benchmark (without chain-of-thought prompting). All baseline numbers are from published reports.
Conclusion
We introduce Autoregressive-to-Diffusion (A2D) vision language models for faster, parallel generation by adapting existing autoregressive VLMs to diffusion decoding. A2D-VL outperforms prior diffusion VLMs in visual question-answering while requiring significantly less training compute. Our novel adaptation techniques are critical for retaining model capabilities, finally enabling the conversion of state-of-the-art autoregressive VLMs to diffusion with minimal impact to quality.
* This work was led by Marianne Arriola during her summer internship at Runway Research. † Research supervisor
References
[1] Z. You, S. Nie, X. Zhang, J. Hu, J. Zhou, Z. Lu, J.R. Wen, and C. Li, "Llada-v: Large language diffusion models with visual instruction tuning," arXiv preprint arXiv:2505.16933, 2025.
[2] S. Li, K. Kallidromitis, H. Bansal, A. Gokul, Y. Kato, K. Kozuka, J. Kuen, Z. Lin, K.-W. Chang, and A. Grover, "Lavida: A large diffusion language model for multi-modal understanding," arXiv preprint arXiv:2505.16839, 2025.
[3] L. Yang, Y. Tian, B. Li, X. Zhang, K. Shen, Y. Tong, and M. Wang, "Mmada: Multimodal large diffusion language models," arXiv preprint arXiv:2505.15809, 2025.
[4] S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y. Lin, J.-R. Wen, and C. Li, "Large language diffusion models," arXiv preprint arXiv:2502.09992, 2025.
[5] J. Ye, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, L. Kong. "Dream 7B: Diffusion Large Language Models." arXiv preprint arXiv:2508.15487 (2025).
[6] S. Nie, F. Zhu, C. Du, T. Pang, Q. Liu, G. Zeng, M. Lin, and C. Li. "Scaling up masked diffusion models on text." ICLR 2025.
[7] S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
[8] M. Arriola, A. Gokaslan, J.T. Chiu, Z. Yang, Z. Qi, J. Han, S.S. Sahoo, and V. Kuleshov. "Block diffusion: Interpolating between autoregressive and diffusion language models." ICLR 2025.
[9] C. Wu, H. Zhang, S. Xue, Z. Liu, S. Diao, L. Zhu, P. Luo, S. Han, and E. Xie. "Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding." arXiv preprint arXiv:2505.22618(2025).
[10] S. Sahoo, M. Arriola, Y. Schiff, A. Gokaslan, E. Marroquin, J. Chiu, A. Rush, and V. Kuleshov. "Simple and effective masked diffusion language models." Advances in Neural Information Processing Systems 37 (2024): 130136-130184.
[11] J. Shi, K. Han, Z. Wang, A. Doucet, and M. Titsias. "Simplified and generalized masked diffusion for discrete data." Advances in neural information processing systems 37 (2024): 103131-103167.
[12] J. Ou, S. Nie, K. Xue, F. Zhu, J. Sun, Z. Li, and C. Li. "Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data." In The Thirteenth International Conference on Learning Representations.
[13] J. Guo, T. Zheng, Y. Bai, B. Li, Y. Wang, K. Zhu, Y. Li, G. Neubig, W. Chen, and X. Yue. "Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale." arXiv preprint arXiv:2412.05237 (2024)
[14] C. Wu, H. Zhang, S. Xue, S. Diao, Y. Fu, Z. Liu, P. Molchanov, P. Luo, S. Han, E. Xie. Fast-dLLM v2: Efficient Block-Diffusion Large Language Model. Blog post. 2025
[15] H. Dong, J. Li, B. Wu, J. Wang, Y. Zhang, and H. Guo. "Benchmarking and improving detail image caption." arXiv preprint arXiv:2405.19092 (2024).
[1] Z. You, S. Nie, X. Zhang, J. Hu, J. Zhou, Z. Lu, J.R. Wen, and C. Li, "Llada-v: Large language diffusion models with visual instruction tuning," arXiv preprint arXiv:2505.16933, 2025.
[2] S. Li, K. Kallidromitis, H. Bansal, A. Gokul, Y. Kato, K. Kozuka, J. Kuen, Z. Lin, K.-W. Chang, and A. Grover, "Lavida: A large diffusion language model for multi-modal understanding," arXiv preprint arXiv:2505.16839, 2025.
[3] L. Yang, Y. Tian, B. Li, X. Zhang, K. Shen, Y. Tong, and M. Wang, "Mmada: Multimodal large diffusion language models," arXiv preprint arXiv:2505.15809, 2025.
[4] S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y. Lin, J.-R. Wen, and C. Li, "Large language diffusion models," arXiv preprint arXiv:2502.09992, 2025.
[5] J. Ye, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, L. Kong. "Dream 7B: Diffusion Large Language Models." arXiv preprint arXiv:2508.15487 (2025).
[6] S. Nie, F. Zhu, C. Du, T. Pang, Q. Liu, G. Zeng, M. Lin, and C. Li. "Scaling up masked diffusion models on text." ICLR 2025.
[7] S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
[8] M. Arriola, A. Gokaslan, J.T. Chiu, Z. Yang, Z. Qi, J. Han, S.S. Sahoo, and V. Kuleshov. "Block diffusion: Interpolating between autoregressive and diffusion language models." ICLR 2025.
[9] C. Wu, H. Zhang, S. Xue, Z. Liu, S. Diao, L. Zhu, P. Luo, S. Han, and E. Xie. "Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding." arXiv preprint arXiv:2505.22618(2025).
[10] S. Sahoo, M. Arriola, Y. Schiff, A. Gokaslan, E. Marroquin, J. Chiu, A. Rush, and V. Kuleshov. "Simple and effective masked diffusion language models." Advances in Neural Information Processing Systems 37 (2024): 130136-130184.
[11] J. Shi, K. Han, Z. Wang, A. Doucet, and M. Titsias. "Simplified and generalized masked diffusion for discrete data." Advances in neural information processing systems 37 (2024): 103131-103167.
[12] J. Ou, S. Nie, K. Xue, F. Zhu, J. Sun, Z. Li, and C. Li. "Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data." In The Thirteenth International Conference on Learning Representations.
[13] J. Guo, T. Zheng, Y. Bai, B. Li, Y. Wang, K. Zhu, Y. Li, G. Neubig, W. Chen, and X. Yue. "Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale." arXiv preprint arXiv:2412.05237 (2024)
[14] C. Wu, H. Zhang, S. Xue, S. Diao, Y. Fu, Z. Liu, P. Molchanov, P. Luo, S. Han, E. Xie. Fast-dLLM v2: Efficient Block-Diffusion Large Language Model. Blog post. 2025
[15] H. Dong, J. Li, B. Wu, J. Wang, Y. Zhang, and H. Guo. "Benchmarking and improving detail image caption." arXiv preprint arXiv:2405.19092 (2024).
BibTeX
@misc{arriola2025ar2d,
title={Adapting Autoregressive Vision Language Models for Parallel Diffusion Decoding},
author={Arriola, Marianne and Venkat, Naveen and Granskog, Jonathan and Germanidis, Anastasis},
year={2025},
url={https://runwayml.com/research/autoregressive-to-diffusion-vlms},
}
title={Adapting Autoregressive Vision Language Models for Parallel Diffusion Decoding},
author={Arriola, Marianne and Venkat, Naveen and Granskog, Jonathan and Germanidis, Anastasis},
year={2025},
url={https://runwayml.com/research/autoregressive-to-diffusion-vlms},
}