
Testing robot policies today requires deploying to physical hardware, a process that is slow, expensive and difficult to scale. Traditional simulators offer an alternative but frequently fail to transfer to the real world, struggling to capture the visual and physical complexity of real environments — from deformable objects and soft materials to non-rigid dynamics that defy standard physical assumptions. A world model that reliably predicts real-world outcomes could fundamentally change how robotics teams evaluate and iterate on policies.
In December, we announced GWM-Robotics, which enables policy evaluation inside a world model without physical hardware. Here, we put it to the test: we simulated eight robot manipulation policies inside GWM-Robotics and compared outcomes against real-world ground truth. Across all eight policies, simulated and real-world scores correlate at 0.95, demonstrating that our world model can serve as a reliable proxy for evaluating robot policies before committing to hardware deployment.
Our early results point to world model simulation as a practical substitute for hardware evaluation, one that compares favorably to existing real-to-sim approaches. GWM-Robotics outperforms PolaRiS, a recent real-to-sim framework that reconstructs specific real-world scenes using 3D Gaussian splatting — a process that involves scanning, reconstruction and manual object setup. Unlike PolaRiS, GWM-Robotics needs only starting images as input. Moreover, GWM-Robotics can generate long rollouts of up to 30 seconds in real time — far longer than comparable world models like Veo Robotics, which is limited to 8-second rollouts.
We're building GWM-Robotics in collaboration with partners including NVIDIA and Berkshire Grey as we scale world models for physical AI. Request access here.
Simulated success
Simulated failure
Methodology: Evaluating Sim-to-Real Correlation for Robot Manipulation
For this study, we took manipulation tasks from the RoboArena benchmark spanning eight vision-language-action policies, with all rollouts using the Franka Emika Panda arm. We used our GWM-Robotics model, a variant of our state-of-the-art Gen-4.5 video generation model, to simulate each policy from the same initial conditions, with each policy generating its own actions in response to observations produced by the world model. We then asked human graders to evaluate the progress the robot made towards each task instruction across 1,450 simulated rollouts — all generated from prior task evaluations in the RoboArena dataset. In total, we collected over 16,000 individual ratings, with each rollout evaluated by ~10 independent graders. By comparing the progress that each policy made between its simulated rollouts and its real-world rollouts, we measure how well simulated outcomes reflect real-world relative performance.
Results
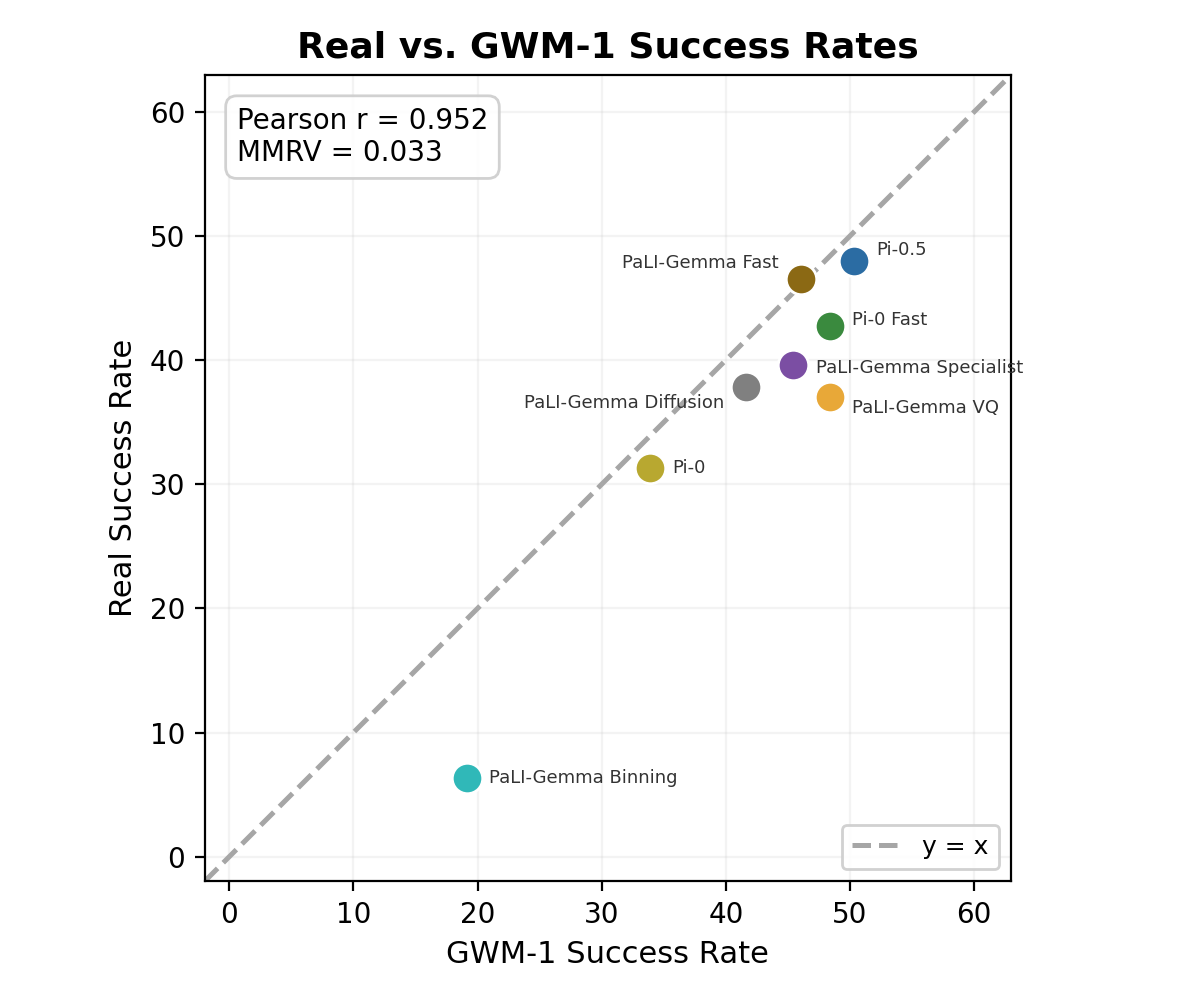
We see that GWM-Robotics produces simulated rollouts that enable reliable policy ranking. Following PolaRiS, we use the Pearson correlation coefficient to quantify agreement between real-world and simulated progress scores, and Mean Maximum Rank Violation (MMRV) to measure rank consistency between the two. Aggregating human evaluators' progress scores across simulated rollouts, the resulting policy rankings match real-world rankings with a Pearson correlation of 0.95 and a Mean Maximum Rank Violation (MMRV) of 0.033, meaning the worst-case ranking error between any pair of policies is negligibly small. When restricted to the subset of RoboArena policy architectures also evaluated in PolaRiS, GWM-Robotics yields a Pearson correlation of 0.986 and an MMRV of 0 — surpassing PolaRiS's correlation of 0.98 and matching its perfect rank ordering. Human evaluators correctly identified the best-performing policy (pi05_droid) and the worst-performing policy (paligemma_binning_droid), while the remaining six policies showed only minor rank inversions between similarly performing models.
Limitations and Future Scope
This study evaluates policy ranking — whether simulated outcomes preserve the relative ordering of policies — rather than absolute success-rate prediction. While rankings are what matter most for practical policy selection, closing the gap on absolute calibration is an active area of work.
Our evaluation here is scoped to tabletop manipulation with a single robot arm (Franka Panda) across tasks from the RoboArena benchmark. While GWM-Robotics has been trained across multiple embodiments, extending our evaluation to those form factors is an important next step. Because the model is built on a foundation trained on large-scale video rather than a single-robot simulator, it can generalize to new embodiments with significantly less robot-specific data than traditional approaches.
Conclusions
These results — across eight diverse policies and over 16,000 human evaluations — demonstrate that our learned world model, trained on large-scale video data and fine-tuned on robot proprioceptive state, can reliably rank robot policies in the same order as real-world execution. This has direct implications for how robotics teams build and test policies:
- Shipping faster: Rather than testing every candidate on hardware, teams can rank policies in simulation and focus physical testing on the top performers.
- Testing at scale without building by hand: Teams can evaluate across varied lighting, object configurations and task setups without manually recreating each scenario in a physical lab.
- Training on less real-world data: A small set of real demonstrations can be expanded by varying objects, environments and conditions — improving generalization without additional data collection.
We believe that building the best world model for robotics requires training on large-scale data that captures the full diversity of real-world physics and interactions. These results support that approach. World model fidelity will continue to improve as we scale training data and compute, narrowing the gap between simulated and real-world outcomes with each generation. GWM-Robotics is a first step, and these early results have accelerated our investment in robotics research as we focus on delivering value to customers today.
GWM-Robotics is a world model trained on real-world video, including physical AI datasets from NVIDIA. We're working with leading physical AI companies, including NVIDIA and Berkshire Grey, to integrate GWM-Robotics into their training and evaluation pipelines. Request access here.