
How we cut model cold-start times from minutes to seconds by broadcasting weights between GPUs instead of downloading them from storage, and the sharp edges we found along the way.
The Cold Start Tax
When a GPU inference worker boots, the first thing it does (before it can serve a single request) is load model weights. For the kinds of models we run at Runway, this means pulling terabytes of parameters from cloud storage, copying them from host memory to GPU memory and calling load_state_dict. For a single worker, this takes minutes. For a fleet of workers rolling out a new model version simultaneously, it's a thundering herd: dozens of machines independently downloading the same bytes from the same storage backend, saturating bandwidth and inflating cold-start times for everyone. We deploy dozens of times a day, often without any model weight changes. Cold starts directly gate autoscaling, rollout speed and user-facing latency and increase the research/engineering feedback loop.
Because model weight changes are relatively rare, deploying so frequently with long cold starts creates an unnecessary tax on GPU inference worker availability and impacts our user experience. The weights already exist on a GPU somewhere in the cluster. A worker that finished setup five minutes ago is sitting there, fully loaded, waiting for tasks. A new worker can receive those weights directly from a peer instead of re-downloading from storage. This keeps generations flowing and allows our research and engineering teams to continuously deliver new functionality. The system makes our clusters nimble: we can quickly rebalance workloads, roll back bad code and maximize the time GPUs spend performing inference.
The Landscape of Approaches
There are several approaches to cold-start optimization, and we've tried most of them.
Faster storage (NVMe caches, parallel chunk downloads) reduces download time but doesn't change the shape of the problem: N workers still make N independent downloads.
Shared memory preloading (/dev/shm, CUDA IPC) eliminates redundant downloads on a single node but is inherently single-machine.
Shared volumes (NFS, EFS, Ceph) can dedupe downloads across machines but add operational overhead and are typically still far slower than GPU-to-GPU transfer.
Distributed caching (Memorystore, custom weight servers) adds another system to operate, capacity-plan, and monitor.
Peer-to-peer transfer is different. One worker downloads and loads weights normally. Every subsequent worker receives weights directly from an already-loaded peer over the GPU interconnect. Download happens once; broadcast scales to the fleet. We built a system called NCCLBack around this idea (named after the NCCL collective it's built on and the fact that it "backs" the weight-loading path, and only tangentially after a certain Canadian rock band).
The reason P2P transfer wins so decisively is physics. GCS download bandwidth, even optimized, lands somewhere around 2–10 Gbps per worker. InfiniBand or RoCE links between GPU nodes deliver 200–400 Gbps. NVLink within a node is faster still, up to 900 GB/s on H100 SXM systems. When you can use a GPU interconnect instead of a storage API, you're moving from the world of "minutes" to the world of "seconds."
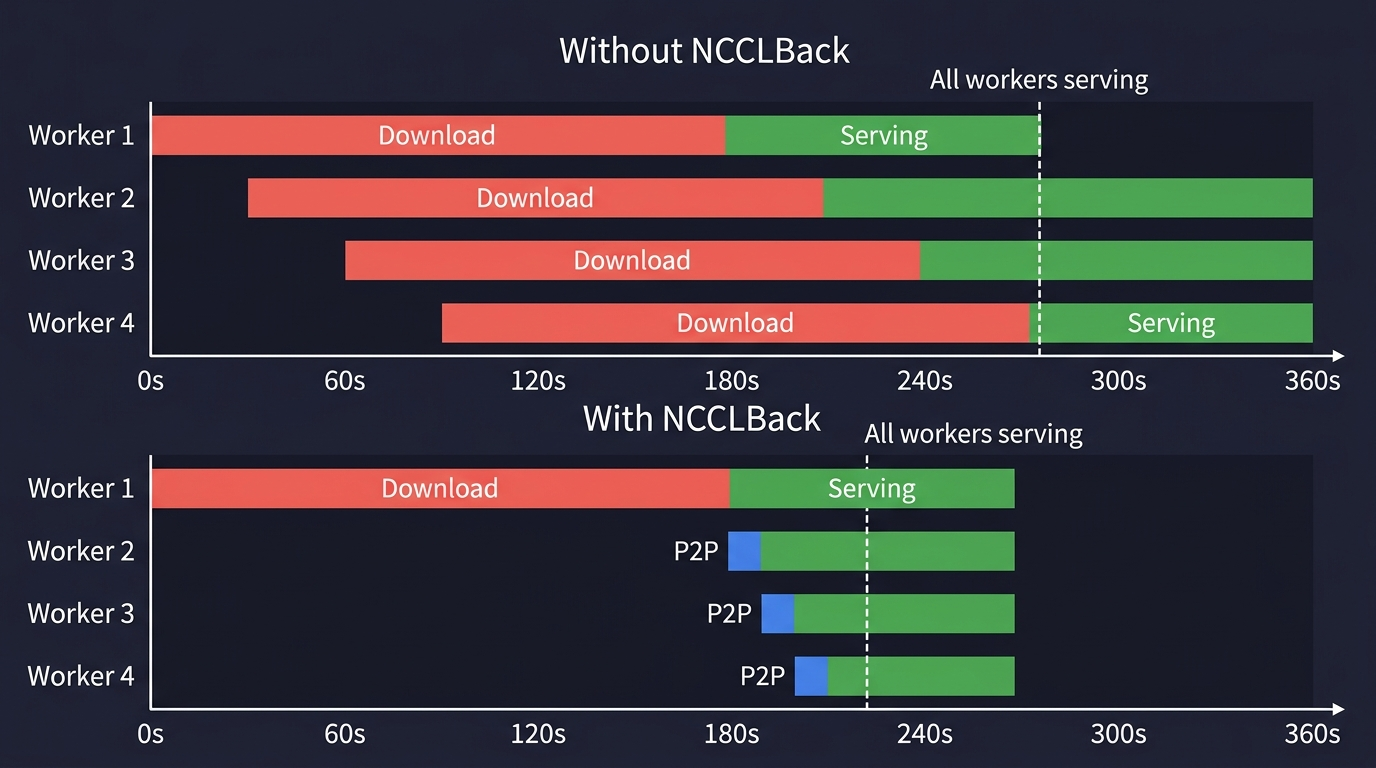
In the traditional model, every worker independently downloads from storage, and cold start time scales linearly with fleet size. With NCCLBack, one worker downloads, and the rest receive weights over the GPU interconnect in seconds:
NCCLBack Design: Building Up in Layers
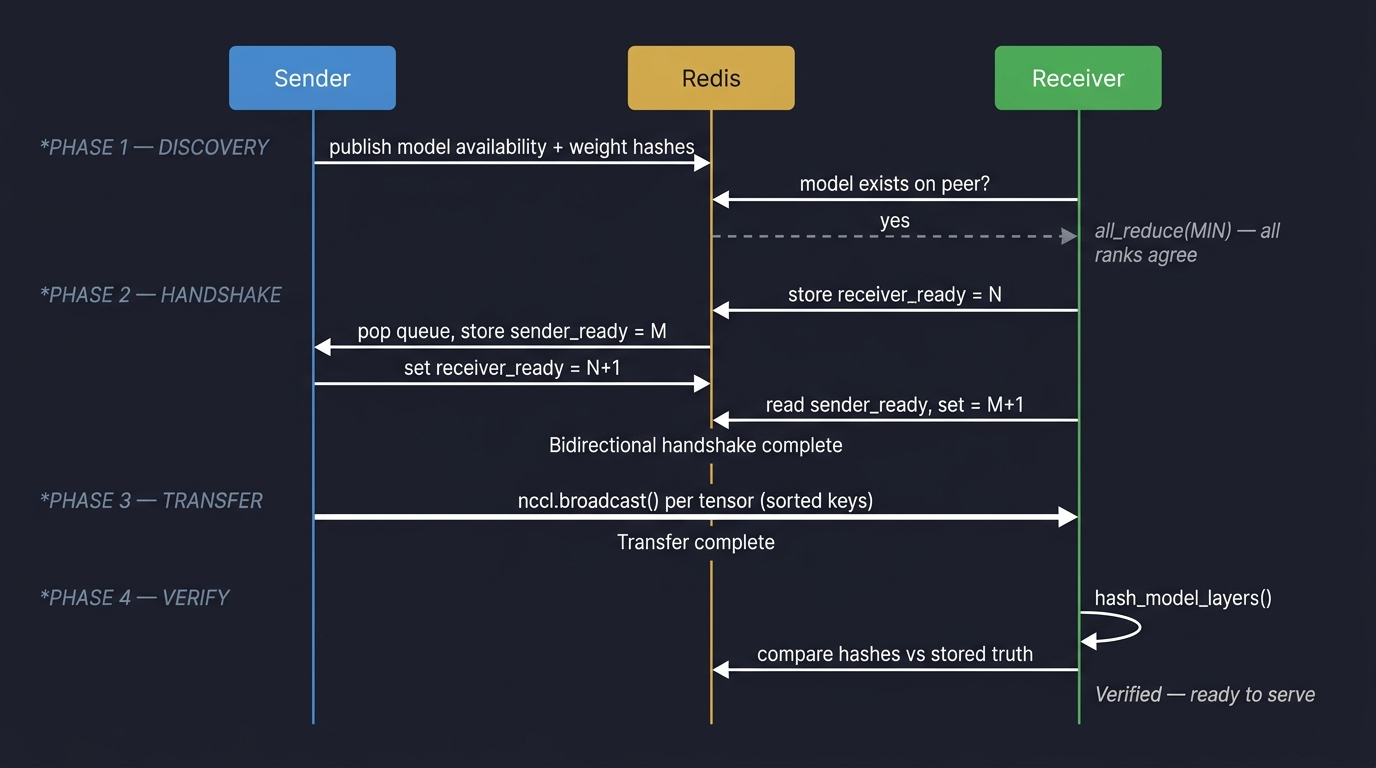
NCCLBack is not a single clever trick. It's a stack of subsystems (discovery, coordination, transfer and verification), each solving a distinct problem. Here's the full protocol at a glance:
Layer 1: The Basic Idea
The core of NCCLBack is a one-to-one weight transfer between two GPU workers using NCCL's broadcast primitive.
The sender is a worker that already has weights loaded on GPU. The receiver is a new worker that has constructed the model structure (all the right tensor shapes, dtypes and devices) but hasn't filled them with values yet. We call this the "skeleton model."
The transfer itself is straightforward. Both sides iterate over model.state_dict() in sorted key order and call nccl.broadcast() for each tensor:
def transfer(model, comm, device_id):
with cp.cuda.Device(device_id), cp.cuda.Stream() as stream:
state_dict = model.state_dict()
# Both sides must iterate in identical order
names = sorted(state_dict.keys())
for name in names:
param = state_dict[name]
# Same call on both sides; NCCL distinguishes by rank
comm.broadcast(
param.data_ptr(),
param.data_ptr(),
param.numel(),
torch_to_nccl_dtype(param.dtype),
0, # root rank (sender)
stream=stream.ptr,
)
stream.synchronize()
Sorting the keys matters more than it looks. nccl.broadcast is a collective: both sides must issue calls in the exact same order, for the exact same tensor sizes and dtypes. If the sender iterates in a different order than the receiver, the broadcast silently writes the wrong data into the wrong buffers and you get a model that produces garbage without any error.
This is the entire data plane. Everything else in NCCLBack exists to make this loop run correctly, safely and without hanging.
Layer 2: Discovery
Before we can broadcast, the receiver needs to find a sender. This is a coordination problem.
We solve it with a Redis-backed queue. When a worker finishes setup and has weights loaded, it publishes two things to Redis:
- Model availability: a key indicating "I have model version X loaded."
- Weight hashes: per-layer integrity hashes (more on this in Layer 5).
When a new worker starts and wants to receive weights, it first checks Redis: does a peer with my model version exist? This check must be unanimous across all ranks in a distributed worker group. If rank 0 thinks a peer exists but rank 3 doesn't, the group will deadlock when some ranks try P2P transfer while others try to download.
We enforce consensus with a pattern that shows up repeatedly throughout NCCLBack:
availability_tensor = torch.zeros(1, device="cuda")
if peer_exists_in_redis:
availability_tensor[0] = 1
torch.distributed.all_reduce(availability_tensor, op=ReduceOp.MIN)
assert bool(availability_tensor[0]) # True only if ALL ranks agree
The all_reduce(MIN) trick: every rank votes, and we proceed only if the minimum vote is 1. If any single rank can't find the model in Redis, everyone falls back to downloading. This is a deliberately conservative choice; we'd rather download redundantly than risk a partial P2P transfer that leaves some ranks with weights and others without.
Model identity matters here. The "model version" is a hash of the model's configuration and checkpoint metadata. In practice, each checkpoint is converted to safetensors format during deployment, and our cloud storage provides a CRC32C checksum for the resulting file. The model config (which includes the safetensors URI and its CRC32C) is then hashed with MD5 to produce the version identifier. This means two workers only consider themselves compatible if they agree on the exact same checkpoint bytes and the same model configuration. Getting this hash wrong means two workers with subtly different model states will try to transfer weights between each other, which either fails loudly (shape mismatch) or fails silently (wrong weights loaded).
Layer 3: Handshake
Finding a peer in Redis isn't enough. Redis tells you a peer existed at some point; it doesn't tell you the peer is still alive and ready to send right now. If we optimistically start a NCCL broadcast and the sender has crashed or is busy, ncclCommInitRank will hang indefinitely. NCCL's collective model has no built-in timeout for communicator creation.
So before we touch NCCL, we run a bidirectional liveness handshake through Redis:
- The receiver stores a random integer at a known Redis key:
receiver_ready:{peer_id}. - The sender polls for that key. When it appears, the sender increments the value by 1 and stores it back.
- Meanwhile, the sender has stored its own random integer at
sender_ready:{peer_id}. - The receiver polls for the sender's key, finds it, increments by 1, and stores it back.
Both sides verify: "I stored X, the other side changed it to X+1." This proves both peers are alive, responsive and talking about the same transfer. The entire handshake runs with short timeouts: 1 second for the sender (who shouldn't wait long for a flaky receiver), 10 seconds for the receiver (who can afford to wait since peers might just be busy).
If the handshake times out, the receiver cleanly falls back to downloading from storage. No NCCL communicators were created, no GPU resources were committed and no cleanup is needed.
Layer 4: The Transfer, with Guardrails
Once the handshake succeeds, we create a 2-rank NCCL communicator (sender = rank 0, receiver = rank 1) and run the broadcast loop. But NCCL has no built-in timeouts — if the peer disappears mid-transfer, the call blocks forever. We wrap both communicator creation and the broadcast loop in a daemon-thread timeout: if the operation doesn't complete within a few seconds, we abort the communicator and raise a TimeoutError. This ensures a hung transfer never blocks the worker from falling back to downloading.
Layer 5: Integrity Verification
After the transfer completes, how do we know the receiver got the right weights? NCCL doesn't provide checksums or integrity guarantees at the application level. A silent data corruption (a flipped bit in a GPU-to-GPU transfer) would produce a model that runs but generates subtly wrong outputs.
We solve this with sampled hashing. When the first worker downloads and loads weights from storage (the "ground truth" path), it computes a hash for each layer of the model and stores those hashes in Redis. Hashing every byte of a multi-gigabyte model is slow, so instead we sample 100 random elements per parameter using a fixed seed (so both sender and receiver sample the same indices) and hash only those samples. We normalize to float16 before hashing so dtype differences between code paths don't cause false mismatches. This turns a minutes-long verification into a seconds-long one, while still catching any corruption that affects more than a vanishingly small fraction of the weights.
The receiver, after receiving weights via P2P, computes the same hashes and compares against the Redis-stored "truth." If any layer's hash doesn't match, we raise a WeightVerificationError and the worker restarts.
The Skeleton Model Problem
NCCL's broadcast doesn't allocate memory. It writes into existing buffers. This means the receiver must have pre-allocated tensors of exactly the right shape, dtype and device before the broadcast starts. We call these pre-allocated tensors "containers" and the model structure they live in the "skeleton model."
Building a skeleton model means running the model's constructor and initialization code while skipping the actual weight loading (passing skip_checkpoint=True). For simple models, this is straightforward. For real production models, it's far more complicated. A video generation pipeline isn't a single nn.Module; it's a graph of submodules (a diffusion transformer, a VAE decoder, text encoders, image embedders etc.), each with its own initialization logic, some of which eagerly load weights during construction.
In pipelined architectures, different GPU ranks host different submodules entirely. One rank might run the VAE decoder while the rest run the diffusion transformer. NCCLBack must return the correct submodule for each rank, because each rank participates in its own independent P2P transfer. The receiver doesn't just need one skeleton; it needs the right skeleton for its rank, with containers that exactly match what the sender will broadcast. Any mismatch (a different dtype, a missing buffer or an extra parameter from a different code path) and the broadcast either crashes or silently corrupts the model. Getting this right required a series of careful abstractions and relentless integration testing across real production model variants.
How It Breaks: A Taxonomy of Failures
Every failure mode below was discovered in production.
The Gray Frame Incident
Some submodules load real weights inside __init__ or instantiate_from_config, not during load_state_dict. When we added NCCLBack to a new model, we called to_empty(device="cuda") on the entire model to prepare skeleton containers. This correctly emptied the diffusion transformer's weights (which would be replaced by P2P transfer), but also wiped the VAE's self-initialized weights, replacing them with uninitialized garbage.
The model ran. It didn't crash. It generated video frames. But the frames were gray: the VAE decoder was applying a learned reconstruction to random noise, producing washed-out structureless output. The failure only manifested on workers that received weights via NCCLBack; workers that downloaded directly were fine, because the download path re-initialized the VAE correctly.
The fix: only empty the specific submodules that NCCLBack transfers.
The FP8 Hash Mismatch
Modern inference stacks often quantize weights after loading (bf16 to FP8) as a post-initialization step. NCCLBack originally hashed weights immediately after downloading, before quantization. When a sender broadcast its FP8 weights to a receiver, the receiver hashed what it got, compared against the bf16 hashes in Redis, and found a mismatch. Verification failed; the worker crashed and restarted.
The fix: hash at the "model is ready to serve" boundary, not the download boundary. Any transformation between download and serve (quantization, pruning or fusion) changes the bytes on GPU, and the integrity hashes must reflect the final state.
The Fallback Trap
For quantized models, the fallback path is a trap. The skeleton model has FP8 containers; the downloaded weights are bf16. If load_state_dict(strict=False) is used, the mismatched keys are silently ignored, and the model loads "successfully" with corrupt weights.
The solution for these models is deliberately drastic: the fallback raises an exception instead of downloading.
def load_model_weights():
raise NCCLBackDownloadFallbackNotSupportedRestartRequiredError()
This forces a restart down the normal download-and-quantize path. Slower, but correct. When a fallback is known to produce a corrupt state, fail fast (and loudly) and take a path you trust.
The Phantom Mesh Change
Early on, the model hash didn't include the device mesh topology. When we changed the tensor parallelism layout, the hash stayed the same (config and checkpoint hadn't changed), so workers with different mesh layouts matched in Redis, attempted a P2P transfer, and hung. The sender had full tensors while the receiver expected sharded ones. The fix was to include a hash of the device mesh in the Redis key namespace so workers with different topologies can't see each other at all.
The lesson generalizes: any dimension along which state_dict() can differ must be reflected in the identity hash.
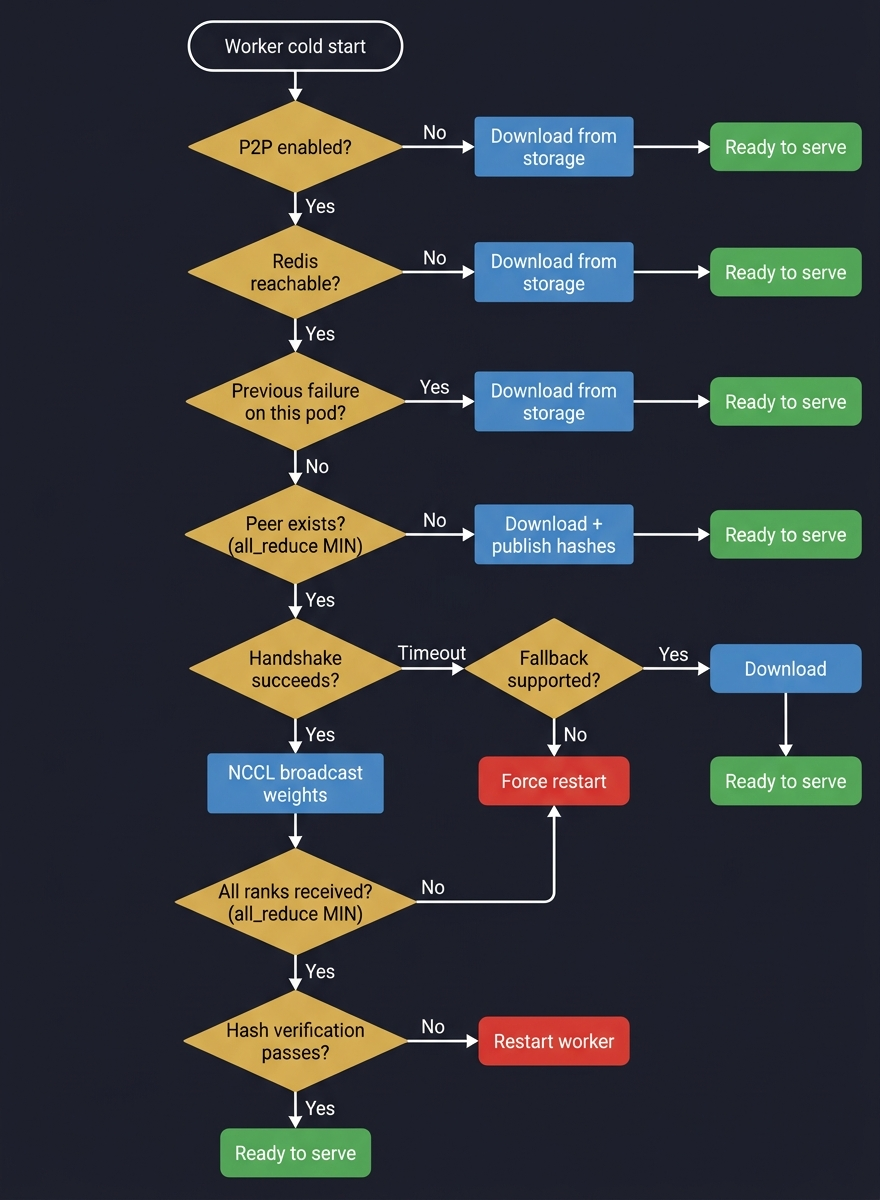
The Full Decision Tree
Putting it all together, here's the full decision tree a cold-starting worker follows. Every "no" branch is a lesson learned from a production incident:
What's Next
NCCLBack started as a cold-start optimization and has become foundational infrastructure. It is deployed across the majority of our inference workloads, including video generation models with varying architectures, sizes and parallelism strategies. Today it saves 347TB per day of transfer and 6,500min per day of inference time.
The natural next step is moving beyond one-to-one transfers. Today, one sender broadcasts to one receiver at a time. Next, we could let multiple receivers participate in a single broadcast so NCCL can use its built-in ring or tree collectives to fan out weights efficiently during large rollouts. Applying the lessons learned from the internet for P2P data transfer to high-speed RDMA networks is a pretty exciting space; if you like the idea of contributing to these types of problems, join us.


