How we built a real-time video agent that transforms any single image — photorealistic human, cartoon mascot or fantasy creature — into a fully expressive conversational character at 24fps, with fast end-to-end latency. Zero fine-tuning required.

Runway Characters is a real-time video agent that turns a single reference image into a fully expressive, conversational video character. Built on GWM-1, our General World Model, it produces natural lip-sync, facial expressions and head motions at 24 frames per second (fps) in HD.
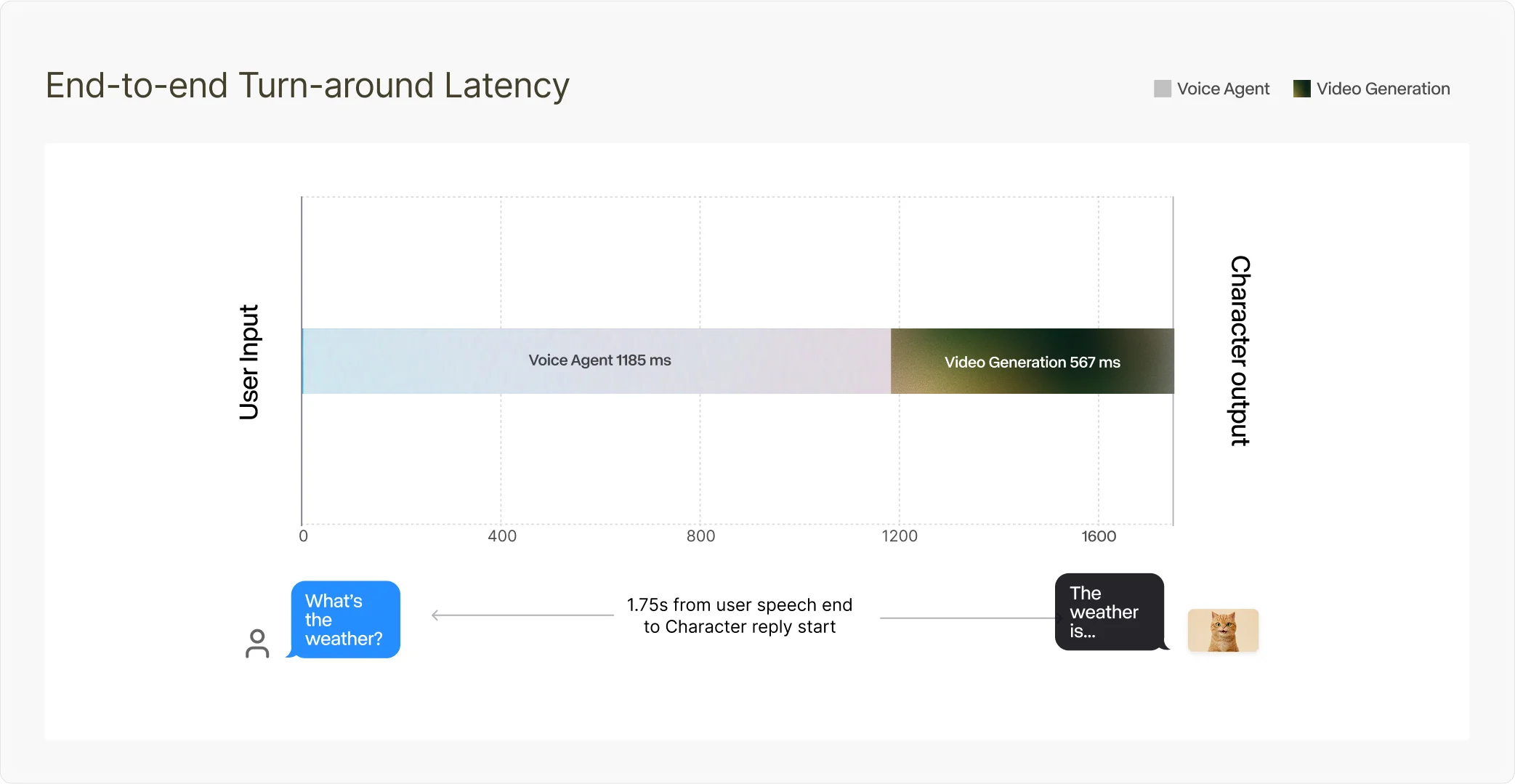
Characters has an effective 37 milliseconds of model time per frame (at more than 24 fps), and 1.75 seconds server-side turn-around from when the user stops speaking to when the character starts responding.
This post covers what makes Characters different: the breadth of what it can animate, how we made it real-time and the product ecosystem we built around the model.
The input to Characters is a single reference image. That's it. The system extracts style directly from the image, and immediately begins generating conversational video conditioned on real-time audio.
Below are 720p clips showing Characters animating a single reference image across styles—from photorealistic humans to cartoons, creatures and brand mascots—with natural, expressive conversation.
24fps in real time: Characters runs at an effective 37 milliseconds (ms) of model time per frame and 1.75 seconds server-side turn-around from end-of-speech to first response frame.
Generating HD video at 24fps in an interactive conversational loop is a fundamentally different engineering problem than offline video generation. Offline, you can spend seconds per frame. In a conversation, you have a frame budget of 42 ms (1/24 seconds) – and that's before audio processing, network transit and the perception of “liveness” that collapses if latency creeps up. In our live sessions, we achieve an effective 37 ms of model time per frame, and 1.75 seconds of server-side turn-around (voice agent + video pipeline) from when the user stops speaking to when the character starts responding.
We make this possible with GWM-1's autoregressive frame-by-frame generation: frames are produced sequentially and streamed to the client as they're generated, instead of iteratively denoising an entire clip.
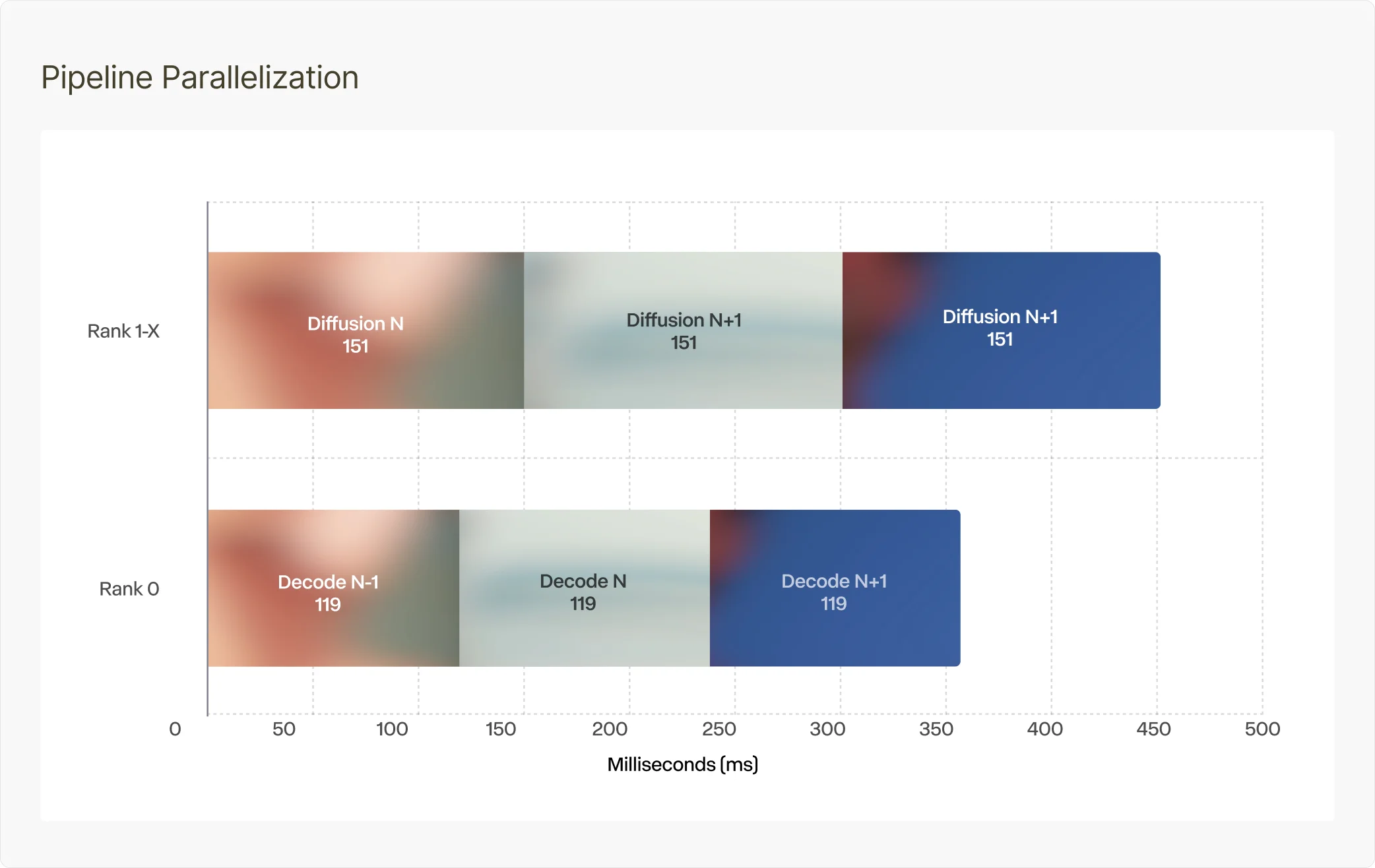
We hit real-time 24fps because of overlap: the diffusion transformer and VAE decoder run concurrently via a pipeline split. That makes the effective iteration cost closer to max(diffusion_time, decode_time) than diffusion_time + decode_time.
Each iteration produces 4 pixel frames, so at 24fps we need one iteration every 167 ms (4/24 seconds). In our measurements, diffusion is 151 ms and VAE decoder is 119 ms; because decode is overlapped, it largely disappears from the critical path. That works out to an effective 37 ms of model time per frame (151 ms / 4 frames), under the 41 ms/frame real-time budget.
Without overlap, diffusion would consume most of the 167 ms budget and decode would push it over. With overlap, decode of frame N−1 runs at the same time as diffusion of frame N.
“Real-time” is also what the user feels end-to-end: the time from when they stop speaking to when the character starts responding. Putting it together: 1185 ms (voice agent) + 567 ms (video pipeline) = 1.75 seconds server-side latency in this session. Client↔server network adds 200 ms on each side (400 ms round trip), depending on connection quality.
The biggest lever to bring this down further is the voice agent: the video pipeline is already fast, and we expect the overall turn-around to drop as we improve voice agent response time.
Below are four of the key model- and systems-level optimizations that make this real-time performance possible:
We shard inference across devices, where the main constraint is communication overhead. We pipeline tensor‑parallel diffusion with VAE decoder on a dedicated device so decode doesn’t contend with the transformer.
Autoregressive video grows the KV cache every frame. Efficient eviction/compression preserves temporal consistency without sacrificing throughput.
Kernel launch overhead can dominate at some resolutions. We capture the forward pass into a static CUDA Graph to reduce overhead, with strict shape/memory constraints.
We tune attention/matmul kernels for our hardware to reduce latency and memory traffic. We use fused Triton kernels help keep the critical path fast.
Getting real-time character video at 24fps is only half the story. To build a useful real-time video agent, you need the surrounding product surface area: ways to ground the character in your domain, connect it to real apps and deploy it where conversations actually happen.
Characters can see your webcam or shared screen during a session for visual workflows like tutoring, demos, games and design feedback.
A character’s voice is core to identity and believability. We make it fast to get “the right voice” with both text-to-voice (design from a prompt) and instant voice cloning (from an audio sample), then assign it to your character for consistent tone across sessions.
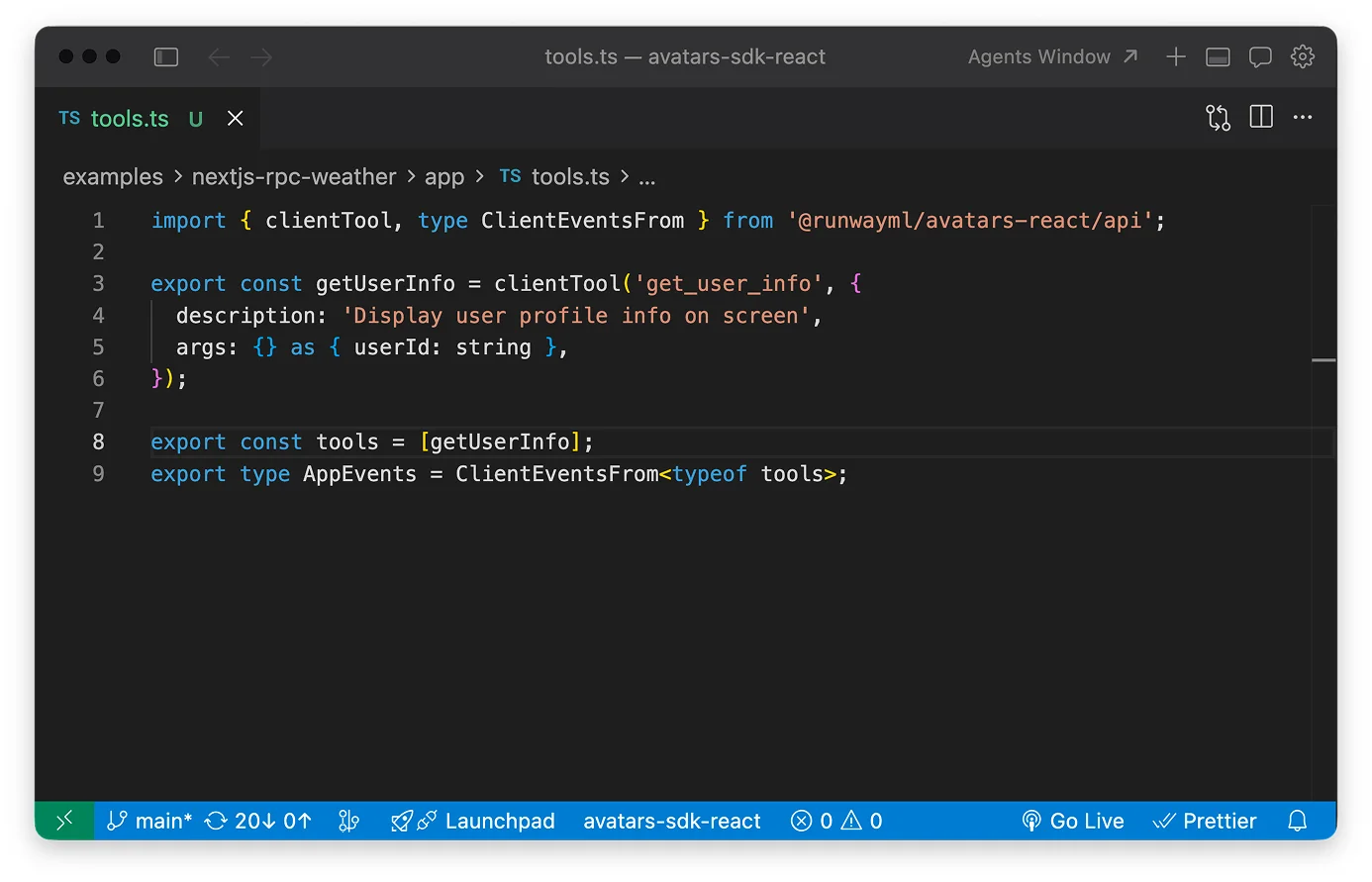
Characters can take actions for you during a session. You define the “tools” they’re allowed to use – anything from UI actions (show captions, pop a trivia card, update game state) to trusted backend RPCs (e.g. fetch_order_status to pull a real status/ETA) whose results feed back into the conversation.
Attach your own documents (text/Markdown) so the character can speak with your company and product knowledge—support docs, FAQs, internal policies, specs—instead of generic responses.
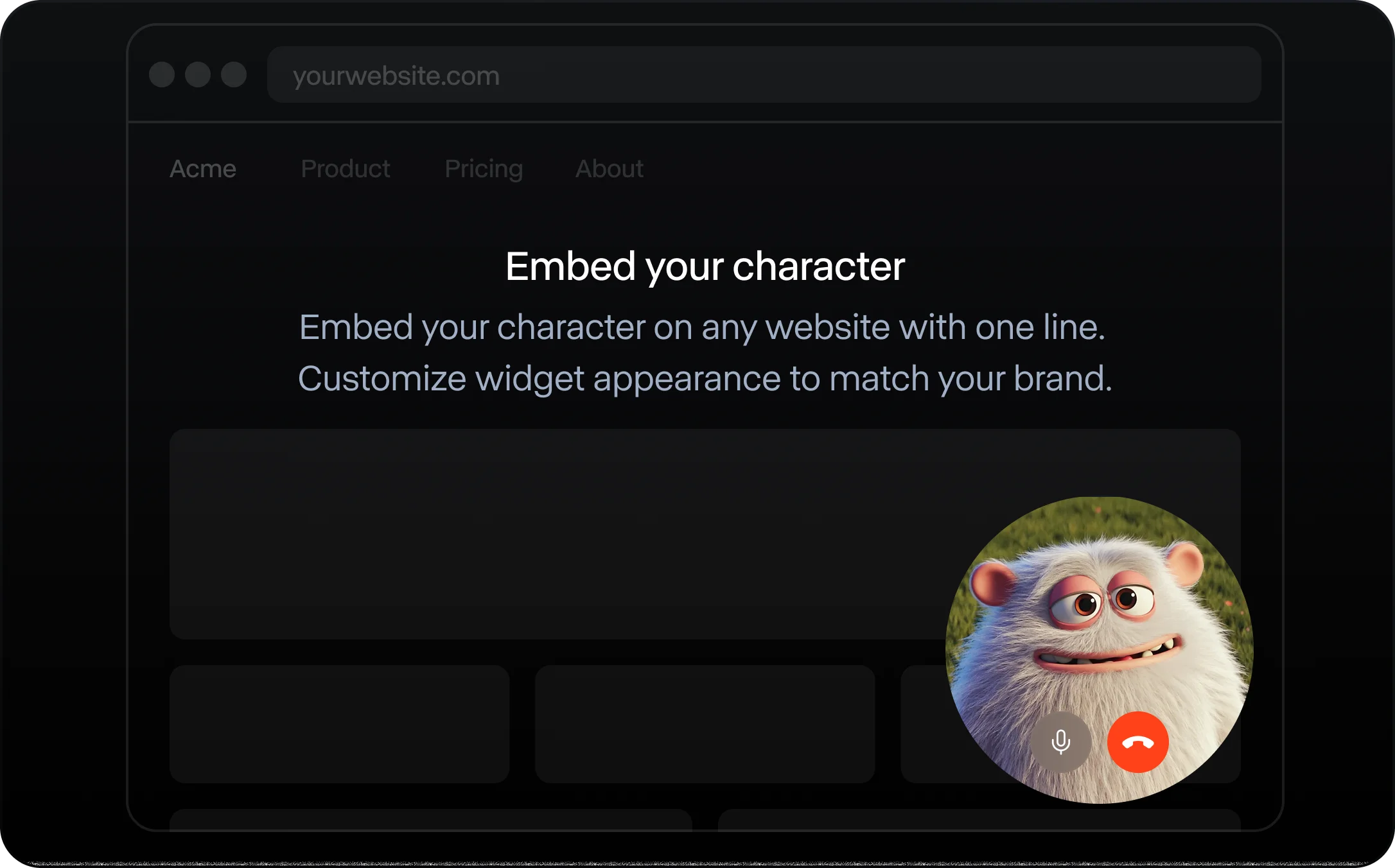
Drop a real-time Character into any web app with a single line of code. The widget handles the real-time plumbing for you, so you can embed avatars in minutes.
Bring Characters into real meetings on Zoom/Google Meet/Teams, so they can see/hear what’s happening and respond in real time, from team standups to customer calls.
Try Characters. Build with us.
Runway Characters is available now via the Runway API and the Runway web and mobile apps. If you love real-time models, low-latency systems and shipping product at the edge of what's possible – we're hiring.
