
We increased GPU utilization by over 20 percentage points while still guaranteeing team capacity by using Kueue as a Kubernetes admission controller: reserved quotas for critical work, a shared queue that borrows idle capacity and preemption to reclaim it when owners need it.
Guaranteed Capacity Without Idle Hardware
Runway trains state-of-the-art video generation models across large GPU compute clusters. Multiple research and production teams share this hardware in isolated environments: some run multi-week pretraining jobs, others serve real-time production inference and others iterate on short experiments. The cluster is expensive and mission-critical, so scheduling becomes a top priority.
We needed two things that usually conflict:
- Guaranteed capacity. Critical training runs and latency-sensitive services need predictable access to GPUs.
- High utilization. Idle GPUs are wasted budget and lost research velocity. If a team has 80 nodes reserved but is only using 50, those 30 idle nodes can represent tens of thousands of dollars per day doing nothing.
Static partitions guarantee capacity but waste GPUs; a free-for-all maximizes utilization but offers no guarantees.
What you actually want is a system that provides guaranteed reservations but automatically lends idle capacity to a shared pool, then reclaims it when the owning team needs it back.
Why We Chose Kueue
Kueue is a Kubernetes SIG project kubernetes-sigs/kueue. It follows Kubernetes API conventions and runs as an admission controller, not a replacement scheduler. This matters: it layers on top of existing Kubernetes primitives rather than introducing its own scheduling binary.
The feature set covers what you need for multi-tenant GPU clusters: gang scheduling, quota management, preemption, workload priority and cohort-based borrowing.
We considered alternatives like Volcano, which have more features. Kueue won for us on simplicity and integration: it works with kube-scheduler rather than introducing a second scheduler binary. For our use case (quota and admission control, not custom placement algorithms), that tradeoff was the right one.
Two areas of active Kueue development are especially relevant to large-scale training:
- Topology-aware scheduling (beta since v0.14). For multi-node training jobs, placement across racks/blocks/zones affects throughput.
- Elastic workloads. Dynamic scale up/down of admitted jobs without suspension or requeueing (still maturing).
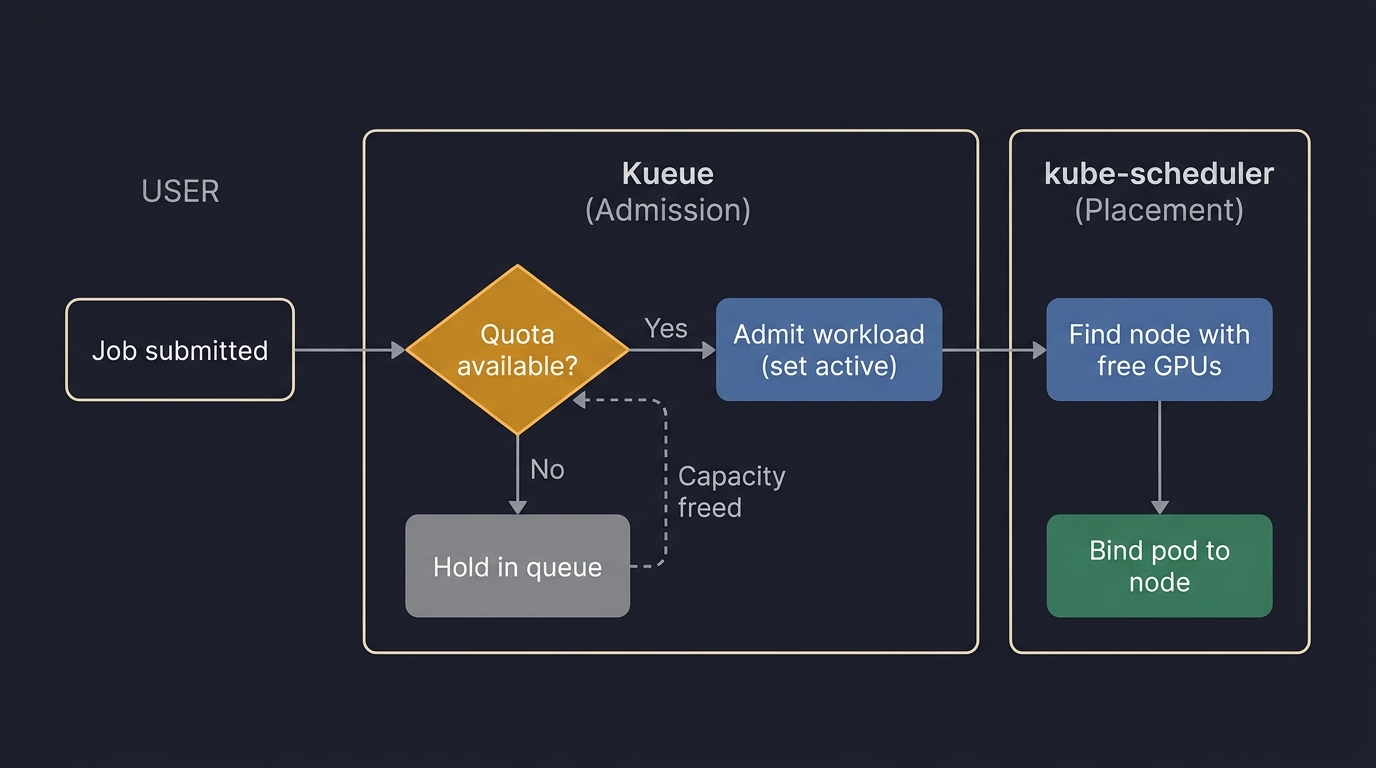
Admission Before Scheduling
Kueue sits between job submission and pod creation. It decides whether a workload should start. Kubernetes’ kube-scheduler decides where admitted pods run.
When you submit a job, Kueue intercepts it before pods are created and checks cluster quota. If quota is available, Kueue admits the workload (marks it active) and kube-scheduler places the pods. If not, Kueue holds it in a queue.
When these two views agree, the system works beautifully. When they diverge (and they will), you get some of the most confusing debugging sessions of your life.
Reserved Queues and the Default Pool
Kueue’s core abstraction is the ClusterQueue: a named bucket with resource quota and rules about how that quota can be used.
Here’s how we structure queues at Runway:
Reserved ClusterQueues are dedicated to teams or projects. Each has a nominalQuota (the number of GPUs it owns). Reserved queues have borrowingLimit: 0: they don’t borrow from others, but they can reclaim any of their quota that’s currently being borrowed.
The default ClusterQueue is the shared, opportunistic pool. It has a small nominal quota of its own, but it can borrow unused quota from reserved queues. When reserved queues are idle or under-utilized, default fills the gap with interruptible work.
Mental model: a parking garage with reserved permits.
- Reserved queues are reserved spaces: permit holders are guaranteed a spot.
- Default is overflow parking: you can park in any empty reserved spot, but if the permit holder shows up you get towed (preempted) and have to come back later.
Beyond reserved and default, we keep a few special-purpose queues (e.g., local development so engineers can iterate against real GPUs without competing with training runs, and data preprocessing for feature pipelines and dataset preparation).
Lending Idle GPUs
All ClusterQueues belong to the same cohort (a set of queues that can share resources). Within a cohort, Kueue tracks each queue’s nominalQuota and current usage; the difference is available to borrow.
Example: three reserved queues plus default.
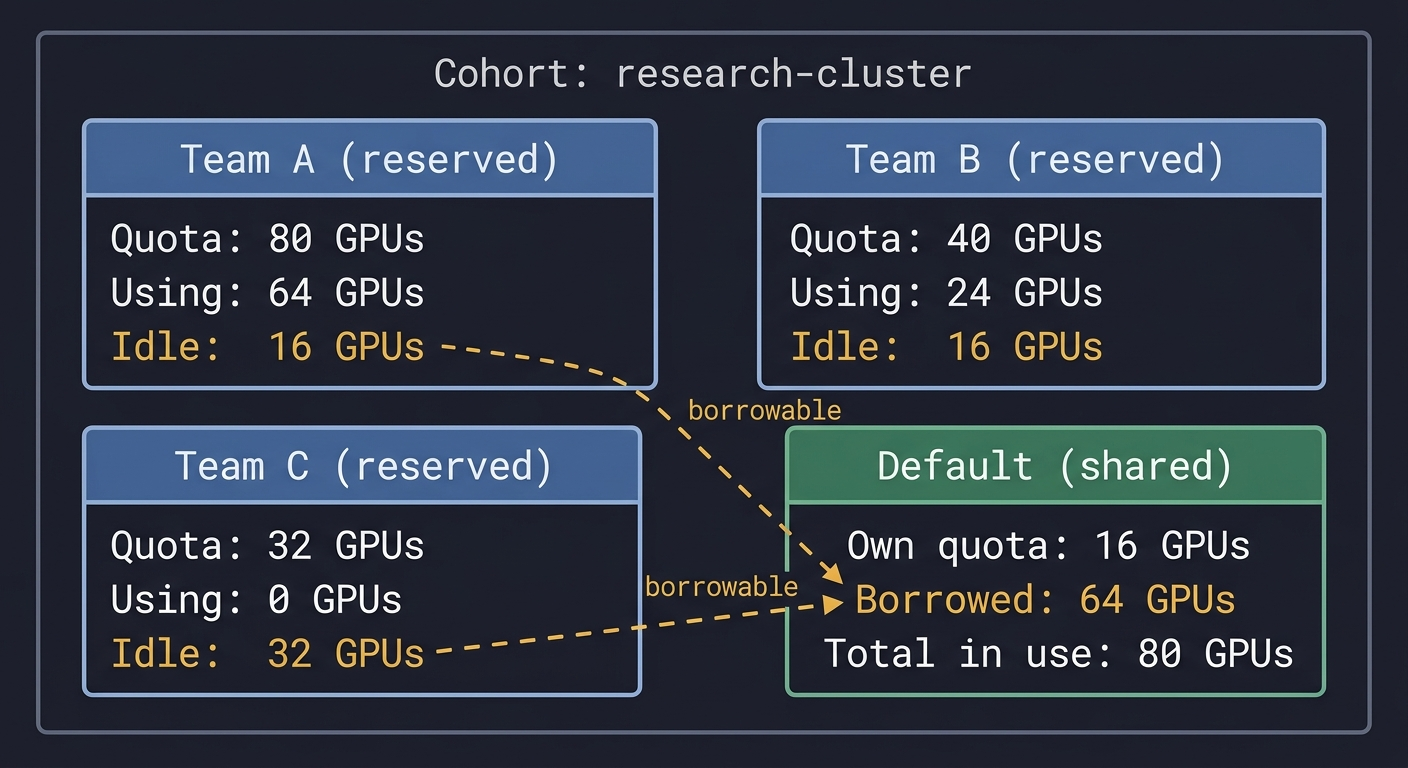
Team A has 80 GPUs reserved but uses 64. Team B has 40 but uses 24. Team C has 32 but uses none. Default can borrow the 64 idle GPUs and run batch evaluations, experiments and other preemptible workloads.
From the outside, default may have a small allocation but huge actual GPU usage. Underneath, every borrowed GPU is accounted to a specific reserved queue, enabling the reclaim path.
Taking Them Back
When a reserved queue needs capacity that default is borrowing:
- Kueue detects the reserved queue is short on quota.
- Kueue selects workloads in default to preempt (lowest Kueue workload priority first; then shortest running time among ties).
- Kueue suspends the selected workloads (terminates pods).
- Once enough quota is freed, Kueue admits the reserved workload.
This is the deal that makes the system work: teams get guarantees because they can always reclaim their quota; default gets high utilization because it accepts interruption. If you submit to default, your job must tolerate preemption.
Preemption Is Not Instant
In practice there can be a 20–30 minute gap between “preemption initiated” and “reserved job running,” driven by:
- Pod termination grace periods.
- Operator-driven teardown (e.g., Ray) and drain sequences.
- Cascading preemptions when default is borrowing heavily.
We mitigate this in two ways:
- Kubernetes-level preemption: we give default workloads a negative pod priority class (e.g., -500) so kube-scheduler evicts them aggressively when higher-priority pods are pending.
- Application-level tolerance: frequent checkpointing, restart-from-checkpoint logic and graceful shutdown handlers.
Two Priority Systems, Two Layers
Kueue and Kubernetes each have a priority system; they’re independent and control different parts of the lifecycle.
| System | What it controls | Where it operates | Example |
|---|---|---|---|
| Kueue workload priority | Admission ordering and Kueue-level preemption within/among queues | Kueue admission controller | Training run (priority 1000) vs routine eval (priority 500) |
| Pod priority class | kube-scheduler preemption: how aggressively nodes are reclaimed | kube-scheduler | Default pods (-500) evicted quickly; reserved pods (0) don't |
In practice, we typically want:
- Default queue: low pod priority (evicted fast) and varying Kueue priorities (control what survives longest).
- Reserved queues: normal pod priority (0) and Kueue priority reflecting internal importance (e.g. large pretraining jobs).
When Quota and Reality Diverge
Kueue reasons about quota, not physical nodes. The key invariant is that allocated quota must not exceed cluster capacity.
In our setup, two configuration sources must stay in sync:
- A Kueue reservations config (ClusterQueue
nominalQuota). - A node pool config (physical capacity).
We enforce this with a CI gate that blocks deploys if total reservations exceed total static capacity.
When this invariant breaks, the symptoms are deeply confusing: Kueue admits a workload (quota looks free) but kube-scheduler can’t place the pods (no nodes are actually available). The workload is “admitted” in Kueue but “Pending” in Kubernetes.
Where the Abstraction Breaks
Admitted but Pending
A workload is admitted by Kueue but pods never schedule. Common causes:
- Quota vs node capacity drift.
- GPU consumers Kueue doesn’t account for (daemonsets, debugging pods, system components).
- Node selector mismatches (the workload targets nodes that don’t exist or aren’t available).
Slow Preemption
Teardown latency can delay reserved jobs even after Kueue suspends default workloads. The bottleneck is usually operators and shutdown sequencing.
Quota Changes Don’t Reshuffle Running Jobs
Reducing nominalQuota doesn’t immediately preempt running workloads. Kueue generally avoids disrupting admitted workloads; reconciliation happens when new submissions require it.
The Phantom Admission
Kueue may admit a workload when quota is free on paper, but the physical resources aren’t yet available (timing gaps between accounting and node reality).
The Full Admission Path
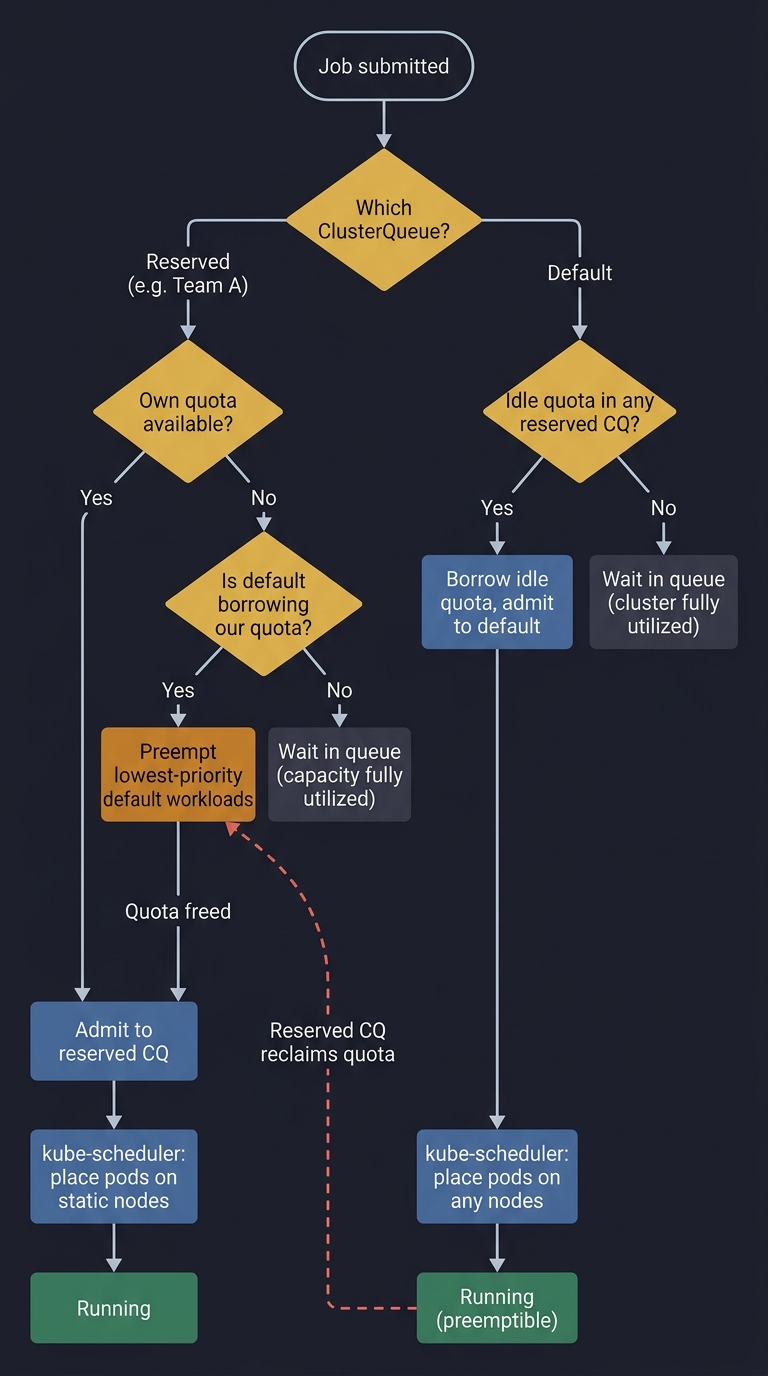
Read this in two passes:
- Happy path: submit → Kueue admits (quota) → kube-scheduler places (nodes) → run.
- Contention path: reserved job arrives → default is borrowing → Kueue preempts default → admits reserved job.
The feedback loop is the point: default runs on borrowed time and yields when reserved work needs capacity.
What We’ve Learned
Admission vs placement is a clean boundary, but you must debug both layers. Most operational pain comes from mismatches between Kueue’s accounting and the cluster’s physical state. Tooling that shows both views side-by-side was the biggest operator-experience win.
Default-as-borrower works. Reserved queues for critical workloads, default for everything else and automatic borrowing kept utilization high without anyone managing it manually. In practice our utilization is ~2x industry norms.
Preemption tolerance is cultural. The rollout wasn’t just config; it required checkpointing, restart infrastructure and clear expectations that default jobs can be interrupted.
Keep configs in sync or suffer. The quota-to-capacity invariant is the most important constraint we operate under. Our CI gate preventing drift has avoided more incidents than any other single check.
GPU scheduling, distributed training infrastructure and cluster orchestration at this scale sit at the intersection of systems engineering and machine learning. If these problems sound interesting, join us. There’s a lot of exciting work to do.


