
This blog post is based on a talk given at PyAI.
This year marks 20 years since the Netflix Prize and even more since MapReduce. Industrial-scale Machine Learning (ML) has been in production for multiple decades, and yet configuring these complicated systems remains a primary challenge across the industry. The tooling has matured, but the config problem hasn't. It keeps getting reinvented the same way. This blog post introduces confingy, an open source library for configuring Python-based ML systems. But first, let's try to understand the origin of this problem via a pedagogical story.
The Evolution of Every ML Codebase
At every company, the same system always gets built. It starts with The Do Everything Script. The Do Everything Script repeats itself, hardcodes string values, uses magic numbers everywhere and reads like the stream of consciousness code equivalent of On The Road. It's usually written to quickly solve a problem. The user assumes it will only be run once, so who cares how ugly it is.
As a concrete example, let's say one wants to use an LLM to classify some text data. The script reads a singular CSV, uses a fixed prompt, calls a specific model and prints out an F1 score.
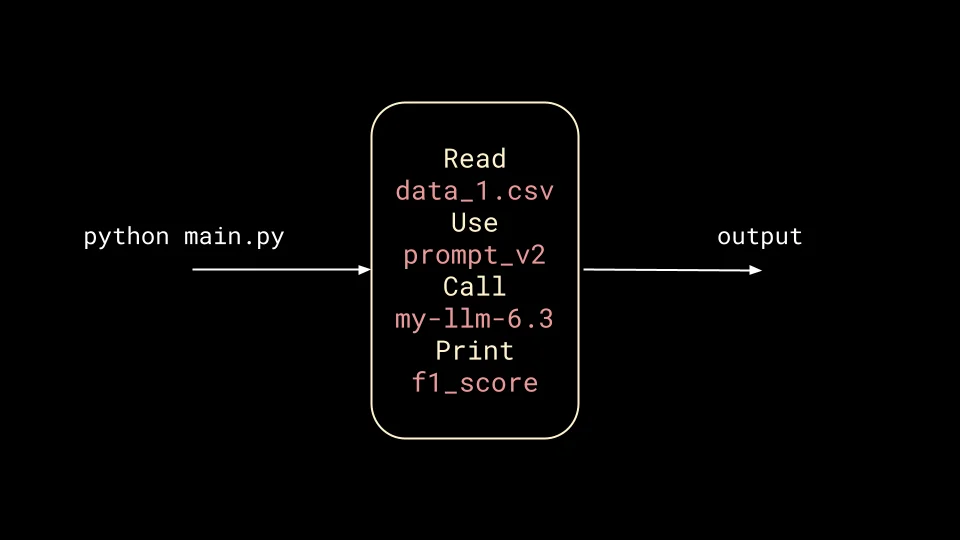
main.py.The script is good enough to provide some real value, but now stakeholders want it to be improved. This requires experimenting with different data, prompts, models and metrics, and the easiest way to do this is by sticking a CLI in between the user and the script.
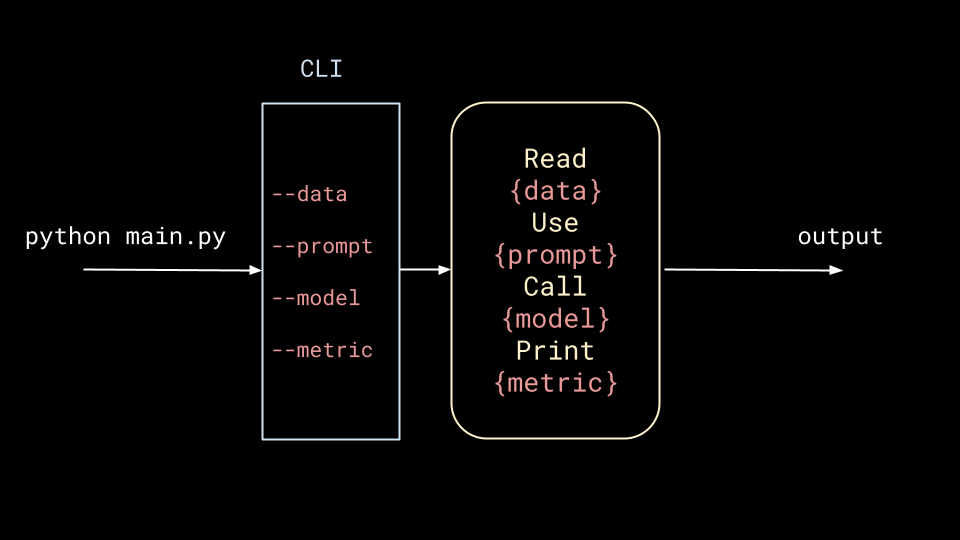
The script drives more value, and further improvements are requested. This only begets more requirements for flexibility, so one often reaches for a YAML configuration file.
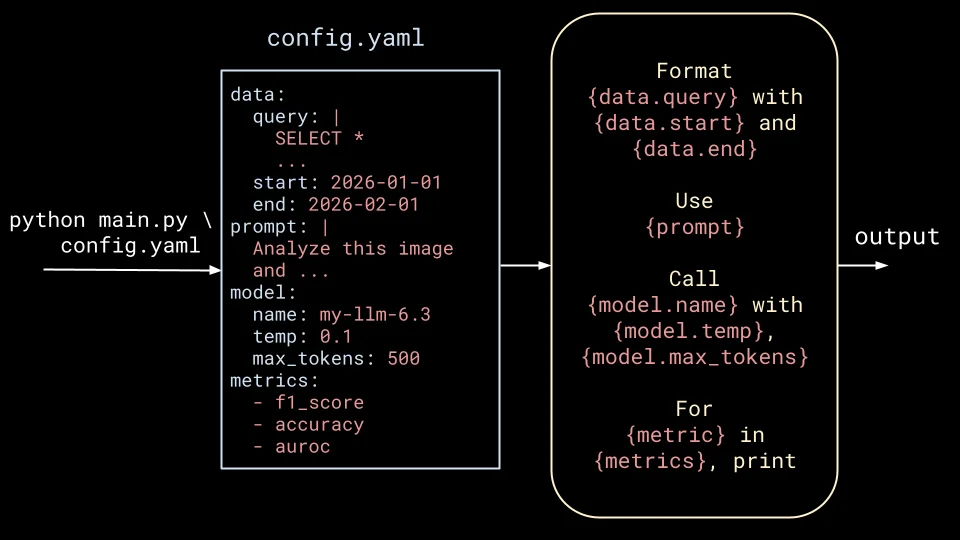
This induces a painful feedback loop of updating the script each time the structure of the config changes, but surely this is the end, right?
Wrong.
Invariably, there will be different data sources to query, complicated prompts to construct and so on, until one realizes that the script should actually be a DAG where each node is a class or function that follows some higher level abstractions.
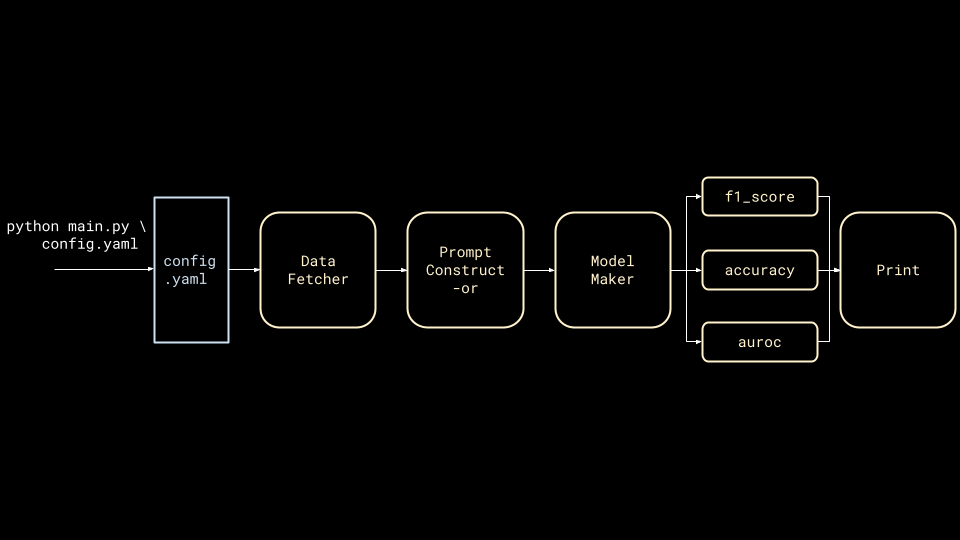
This pattern is at odds with a YAML config because it's unclear how to specify and instantiate classes from YAML. Commonly, people end up reaching for YAML tags and implementing string-based dynamic class instantiation, and this is where ML codebases often evolve to across the industry.
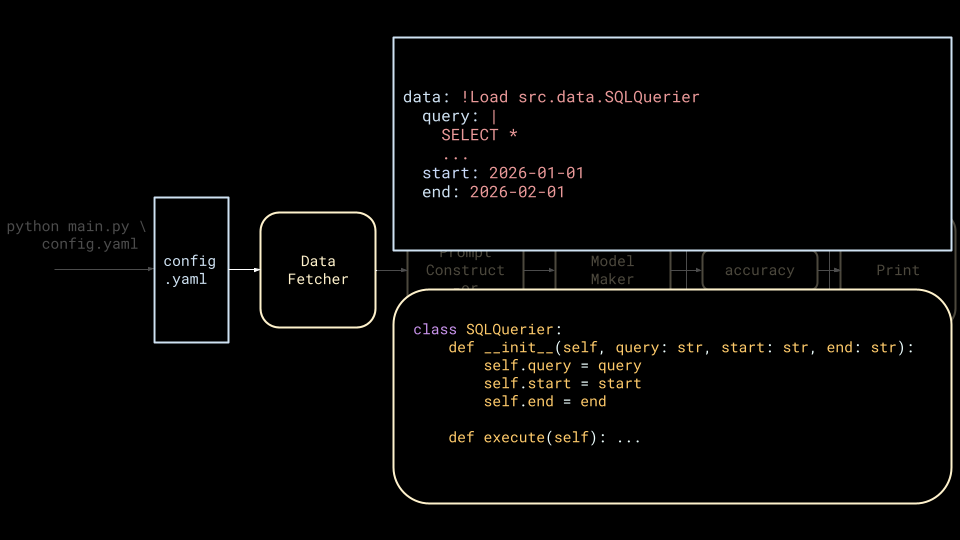
This is the system that gets built at every company. Now let's talk about why it's so painful to live with.
The YAML Trap
All of those ML codebases end up drowning in complexity and terrible developer experience.
By pushing so much logic into configuration, one eventually ends up transforming YAML into a Turing-complete DSL. At Runway, we relied on OmegaConf to expand our need for control. We built a system that allowed configs to inherit from other configs by unioning fields at any arbitrary depth. A single config could inherit from a web of other configs. We supported global variables that could also be overwritten via this inheritance system. We added tags to support inline execution of string-based python code. A single training config ended up as thousands of lines of YAML inherited from dozens of files.
The developer experience was just as bad. Cmd-clicking to go to a function definition doesn't work on classes defined as strings YAML. When the parameters of the class' constructor are a YAML dictionary, we lose modern type hinting and validation. Refactoring classes is impossible when we can't easily see which classes are being used in production when they're spread across configs.
Beyond all of this, using YAML configs in this way actually hurts the code structure. If all of the classes are dynamically instantiated from YAML configs, then dependency injection becomes annoying since all classes must now support dynamic instantiation. As a result, one must either choose inheritance over composition or create God Classes with continually growing constructor flags.
Just Write Code
At first pass, it seems like one should just be able to write code. Use a dataclass or pydantic model and simply set the classes as fields.
from dataclasses import dataclass
from src.data import BaseQuerier, SQLQuerier
@dataclass
class Config:
data_fetcher: BaseQuerier
...
my_config = Config(
data_fetcher=SQLQuerier(
query="""
SELECT *
FROM my_table
WHERE
date BETWEEN {start} AND {end}
""",
start="2026-01-01",
end="2026-02-01"
),
...
)
Unfortunately, this runs into two problems:
- How to track the arguments to the class constructors?
Reusability of code is important in experimental workflows – especially in AI, where billion dollar companies do this as a service. In the above example, how does one keep track of the start and end dates for a particular run of the job?
- What if the classes are too "expensive" to instantiate when creating the config?
Maybe the class connects to the database upon instantiation. Maybe it allocates a trillion parameters worth of memory for an LLM. Maybe the config will be defined locally but won't be run until its on a remote machine. In all of these scenarios, one needs to be able to define the object now but lazily instantiate it.
Sometimes people solve for these problems by associating a config class with every class.
from dataclasses import dataclass
from src.data import BaseQuerier, SQLQuerier, SQLQuerierConfig
@dataclass
class Config:
data_fetcher_class: type[BaseQuerier]
data_fetcher_config: dict
...
my_config = Config(
data_fetcher_class=SQLQuerier,
data_fetcher_config=SQLQuerierConfig(
query="""
SELECT *
FROM my_table
WHERE
date BETWEEN {start} AND {end}
""",
start="2026-01-01",
end="2026-02-01"
),
...
)
data_fetcher = (
my_config
.data_fetcher_class
.from_config(
my_config.data_fetcher_config
)
)
While this works, it's a major drag. It will encourage inheritance over composition, because who wants to go through all that boilerplate for a new class?
Everything up to this point crystallizes into the four requirements that any real solution has to satisfy:
- Everything should be Python.
- Track constructor arguments.
- Lazy instantiation.
- Don't make me refactor my entire codebase!
Meet confingy
confingy is a Python library that supports the above requirements. Internally, we have migrated all of our YAML configuration over to confingy. You may wonder how we pulled off such a feat, but it turns out refactors are easy when people hate the existing system enough.
The library has four main capabilities: serialization/deserialization, lazy-loading, validation and transpilation. All of them fall out naturally from a single @track class decorator:
from confingy import track
@track
class SQLQuerier:
def __init__(self, query: str, start: str, end: str):
self.query = query
self.start = start
self.end = end
def execute(self): ...
querier = SQLQuerier("SELECT * FROM table", "2026-01-01", "2026-02-01")
When a tracked class is instantiated, confingy stores the constructor arguments and other information about the class in a private _tracked_info attribute on the object. In doing so, many features fall out.
Serialization and Deserialization
confingy can serialize any tracked object to JSON. It even tracks a hash of the class' code.
from confingy import serialize_fingy
print(serialize_fingy(querier))
{
"_confingy_class": "SQLQuerier",
"_confingy_module": "my_script",
"_confingy_init": {
"query": "SELECT * FROM table",
"start": "2026-01-01",
"end": "2026-02-01",
},
"_confingy_class_hash": "3aa6871...",
}
Serialized "fingys" can then be deserialized back into Python.
from confingy import deserialize_fingy
print(deserialize_fingy(serialize_fingy(querier)))
# <my_script.SQLQuerier object at 0x7c670313c0d0>
If a constructor argument is also tracked, then it will be nicely serialized, yielding dependency injection for free. Let's take the following classes that all stack inside of each other, Matryoshka-style.
@track
class DBConnector:
def __init__(self, connection_string: str):
self.connection_string = connection_string
def connect(self): ...
@track
class SQLQuerier:
def __init__(self, db: DBConnector, query: str, start: str, end: str):
self.db = db
self.query = query
self.start = start
self.end = end
def execute(self): ...
@track
class Dataloader:
def __init__(self, querier: SQLQuerier, batch_size: int):
self.querier = querier
self.batch_size = batch_size
def load(self): ...
They can be packaged up into a single dataclass field:
@dataclass
class Config:
data: Dataloader
config = Config(
data=Dataloader(
SQLQuerier(
db=DBConnector("postgresql://user:pass@host:port/db"),
query="SELECT * FROM table",
start="2026-01-01",
end="2026-02-01",
),
batch_size=128,
)
)
They can then be clean serialized (and deserialized!) as a nest of JSON:
{
"_confingy_class": "Config",
"_confingy_module": "my_script",
"_confingy_dataclass": true,
"_confingy_fields": {
"data": {
"_confingy_class": "Dataloader",
"_confingy_module": "my_script",
"_confingy_init": {
"querier": {
"_confingy_class": "SQLQuerier",
"_confingy_module": "my_script",
"_confingy_init": {
"db": {
"_confingy_class": "DBConnector",
"_confingy_module": "my_script",
"_confingy_init": {
"connection_string": "postgresql://user:pass@host:port/db"
},
"_confingy_class_hash": "21d1d02cf..."
},
"query": "SELECT * FROM table",
"start": "2026-01-01",
"end": "2026-02-01"
},
"_confingy_class_hash": "3aa687197d..."
},
"batch_size": 128
},
"_confingy_class_hash": "6630e2d4..."
}
}
}
Lazy-loading
Any tracked class also gets a .lazy() classmethod. Passing the constructor arguments to this method will create a lazy version of the class
from confingy import Lazy, track
@track
class DBConnector:
def __init__(self, connection_string: str):
self.connection_string = connection_string
def connect(self): ...
lazy_db = DBConnector.lazy("postgresql://user:pass@host:port/db")
print(lazy_db)
# Lazy<DBConnector>(
# config={'connection_string': 'postgresql://user:pass@host:port/db'}
# )
db = lazy_db.instantiate()
Lazy classes even play nicely with types. The below code will play nicely with mypy, assuming you have added the confingy mypy_plugin.
from confingy import Lazy, track
@track
class SQLQuerier:
def __init__(self, db: Lazy[DBConnector], query: str, start: str, end: str):
self.db = db
self.query = query
self.start = start
self.end = end
def execute(self):
connection = self.db.instantiate().connect()
...
Validation
While lazy-instantation is nice, lazy-failing is bad. There's no reason to wait until a cluster is spun up to realize that a string was passed for a float argument. confingy not only tracks constructor arguments, it also parses the constructor parameter names and type hints. As a result, confingy will raise validation errors for both lazy and non-lazy classes.
@track
class DBConnector:
def __init__(self, connection_string: str):
self.connection_string = connection_string
def connect(self): ...
lazy_db = DBConnector.lazy(99.1)
# confingy.exceptions.ValidationError: Validation failed for DBConnector:
# • Field 'connection_string': Input should be a valid string (got 99)
#
# Provided configuration:
# connection_string: 99
Transpilation
When a confingy-serialized object is deserialized back into Python, it's hard for a user (or computer or agent) to understand what is inside of this object. While one can open the object in a REPL and tab-complete on its attributes to see what was inside, this is suboptimal. Ideally, one would be able to see the original Python code that produced the serialized object. With confingy.transpile_fingy, a serialized object can be transpiled back into the Python that would have produced it. This Python can then be checked into version control, inspected in an IDE and so on.
Open Source & What's Coming
confingy is now open sourced and installable via PyPI. We welcome feedback and contributions. While it is feature complete enough to replace our old YAML setup, there are always things to work on. For example, the serialization support can be limiting (e.g. we do not yet support Pydantic). We're also still trying to figure out best practices in this brave new world of code as config. What's the best way to diff changes? How should we handle mutability and immutability?
While configuration is clearly not "solved," and will likely never be, we now (thankfully) spend much less time trying to solve it.
Many thanks to Wei Zhang, Elad Richardson, Pablo Acuaviva, Daniel Mendelevitch, Nasir Khalid and Kamil Sindi for ideas, support and stress-testing of confingy.
If you've found yourself fixing or fighting configuration systems, join us — there's a lot of exciting work ahead.


