Elements of disruption — the noise inside learning machines






Since Friedrich Kittler we know that noise is not only disturbing our messages, rather it is the message itself — that wants to be decrypted. When looking at images of machine learning, one common pattern is noise. Instead of suppressing this noise, I want to take a close look in this visual exploration. This project was created as part of the Runway Flash Residency.
When looking at these machine generated images, what you commonly see, are very distinct artefacts. Moments of distortion, that so many engineers are probably trying to fighting right now. But instead of fighting it, I want to take a closer look at the noise produced by these machine learning algorithms.
When training Neural Networks on poster designs one thing become apparent: The machine has a different notion of typography. Overall it has a different understanding of what an image is. This was one of the starting points for my exploration.

The process
I did a series of explorations to look into the visual output of different machine learning models.
The technical setup
I mostly used the p5.js online editor to create fast and simple sketches as starting points for experimentation. The hosted models of Runway can easily be implemented and called through a .fetch() function. It is even quite straight forward to convert the canvas into base64 images using the pg.canvas.toDataURL() function. Through this it is super simple to send any graphic (even shaders) to runway and display the image back into the sketch. The way promises work with this API is quite nice, because it makes it easy to wait for the image to be processed, or to know when a model is sleeping or awake.
Exploration 1: A raw visualisation of neural networks
I first started off looking into simple neural networks. I was interested what kind of visuals one could get out of such basic networks. I tried to figure out how the weights in such a network could be visualised.
Every rectangle is a completely randomised neural network taking x and y as input and returning r, g, b as output. This visualises the pure nature of the neural network itself.

Exploration 2: Applying depth maps to shaders.
One approach that already stuck with me after the first exploration, was the repurposing, not necessarily mis-use, but rather use in a different way then intended. This is why I wanted to see what is possible with using depth maps. Having worked with shaders and raytracing before, I knew that it can be quite tricky to calculate the depth within 3D images. But through depth maps it is quite simple to get estimations of depth within graphics and image. This is why I wanted to visualise the depth of image or graphics with colors in shaders.
This is a simple p5.js sketch, that uses Runway’s hosted models and WebGL shaders. I am feeding an image into a depth-map model and the result of that is used by the shader to map the depth to certain colours and movements.
Exploration 3: Training a GAN on 6.000 images of books
After these first explorations, I decided to train my own model. I scraped 6.000 images of book design from the internet and fed it into a GAN. The resulting images have a very interesting notion of what typography could look like if one couldn’t read. It is almost like cryptographic signs. This lead me to become more interested in the noise of these models. So I started to make these elements of disruption more visible, by amplifying them.

Exploration 4: Using noise as a tool to explore images generated by machine learning
Through the previous experiments I got interested in the very distinct artefacts that these models produce. I want to explore this noise in a visual way. That’s why I built a tool to look at these images and to distort them, to amplify certain parts or to completely mess up the images.
Amplifying the noise: If this is these are the aesthetics of machine learning then we should reflect on it and use it, amplify it.
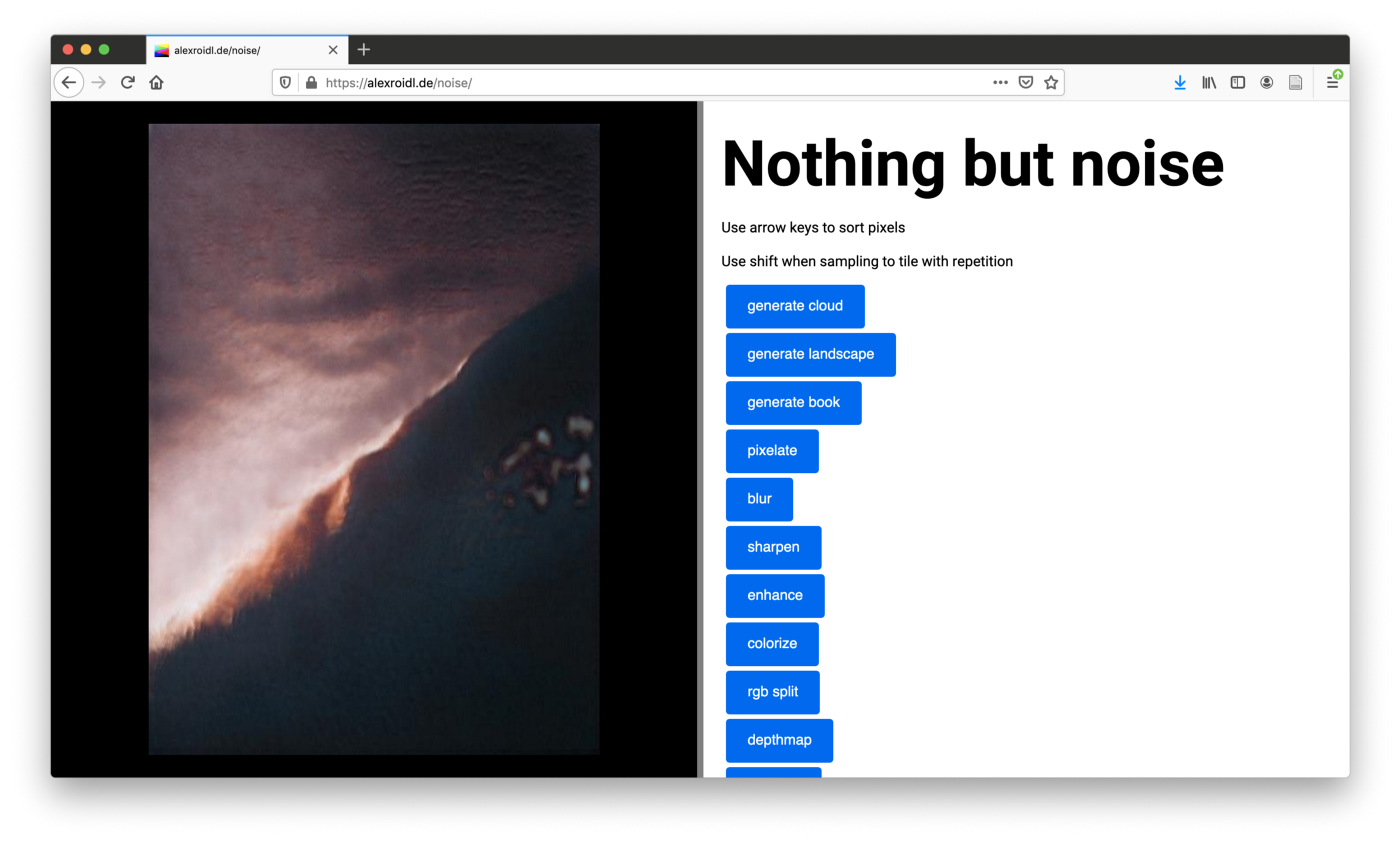
The tool is available here: https://alexroidl.de/noise/
The tools is build on-top different javascript libraries: p5js, panandzoom, splitter.js and using hosted models to generate images. The idea is to always start out with generated images like clouds, landscapes or books.
There are different functions to then ‘investigate’ these images:
(use the arrow keys to pixel sort): the pixels will be sorted by hue and brightness once you press the arrow keys
generate cloud: is generating images of clouds, they look very abstract in itself, almost like noise algorithms do.
generate landscapes: trained on google satellite images, this model generates strange images of non existing landscapes.
generate books: the model I am describing on top, being trained on 6000 images of books
pixelate: pixelate the image to see the bigger picture
blur: blur function to get rid of structures
sharpen: to amplify the structures
enhance: dreaming new patterns into the image
colorize: transforming the brightness of pixels to colors
rgb split: split and shift the rgb colors
depthmap: model to calculate the depth inside the image, returns a black and white image
saturate: amplify the saturation of the image
save: save the image
sampler: check this function to resample parts of the image. select the area that you want to zoom into.
tile: when in sampler mode, tile means to repeat the selected area instead of zooming in
auto sort pixel: is sorting the pixels in a continuous motion.
Conclusion
There are so many things that still need to be explored with these kind of algorithms. And I think that the important parts are those that are hidden, that lay under the surface — the noise that makes the message readable instead of invisible.
Runway provides a great way to make these weird algorithms accessible to creatives and artist. Through this there are a lot of opportunities to look into these models from different perspectives. I really found it interesting to find ways to subvert or misuse those models to generate different means. This use in a different context gave me a lot of different ideas and hints how these models could be used in a practice of information visualisation or graphic design. Maybe because of this, we will start to understand the impact of such images and how they can be used in other practices in the future. (Not only for creating ‘surprising’ images of faces)
Thanks to Runway for the generous support and for making this research possible.
www.alexroidl.de
www.instagram.com/alexanderroidl/
www.twitter.com/AlexRoidl
