Distributing Work: Adventures in Queuing


At Runway, we build professional video editing tools for the web. Our product gives users access to powerful VFX techniques like rotoscoping and content-aware video in-painting, which rely on compute-intensive algorithms for real-time video processing and leverage state-of-the-art hardware behind the scenes.
In this post, we'll outline some of the engineering challenges we've faced around streaming video, talk about some of the approaches we've taken to solve them, and then reflect on the benefits we've gained in the process.
Let's jump into the weeds.
Sequel Video Serving
Building a robust video streaming pipeline is core to our product. As a browser-based video editor, we offload many video processing effects to our server infrastructure. Once a user uploads a video, our streaming servers facilitate video playback by serving it to the user's browser. When they use Green Screen, our built-in rotoscoping tool, our streaming servers are responsible for decoding their video into a collection of frames, performing complex operations on these frames using custom machine learning models, re-encoding the frames as video, and then transporting them to a browser using HTTP Live Streaming (HLS). Often, these tasks are performed while racing a playhead; if our servers don't respond quickly, a user will experience a spinning loader while their media renders.
Speaking generally, browsers generate compute-intensive workloads and ship them off to our streaming servers, expecting to receive a response as soon as possible.
- The faster the average response times are, the fewer video playback delays and interruptions a user experiences.
- The less variance in response times, the more reliable the product feels.
Our servers stream video back to browsers in video segments of fixed length, say three seconds. If a user is playing a two minute video with a rotoscoping mask effect applied to it in real-time, each HTTP request to render the video effect must complete in less than three seconds or else their experience will be interrupted.
# Here's a collection of HTTP requests which a browser client would
# make on behalf of a Sequel user to stream a two minute video with
# an effect applied to it.
GET /segment.mp4?start=0&end=3&effect=rotoscope
GET /segment.mp4?start=3&end=6&effect=rotoscope
...
GET /segment.mp4?start=117&end=120&effect=rotoscope
Breaking Down the Problem
At a high level, we can think of these expensive HTTP requests as work that needs to be done and our streaming servers as workers which can do that work.
In our scenario, the time it takes to complete each work item can be broken down into two periods:
- The time work is waiting to be worked on.
- The time a worker spends working on it.
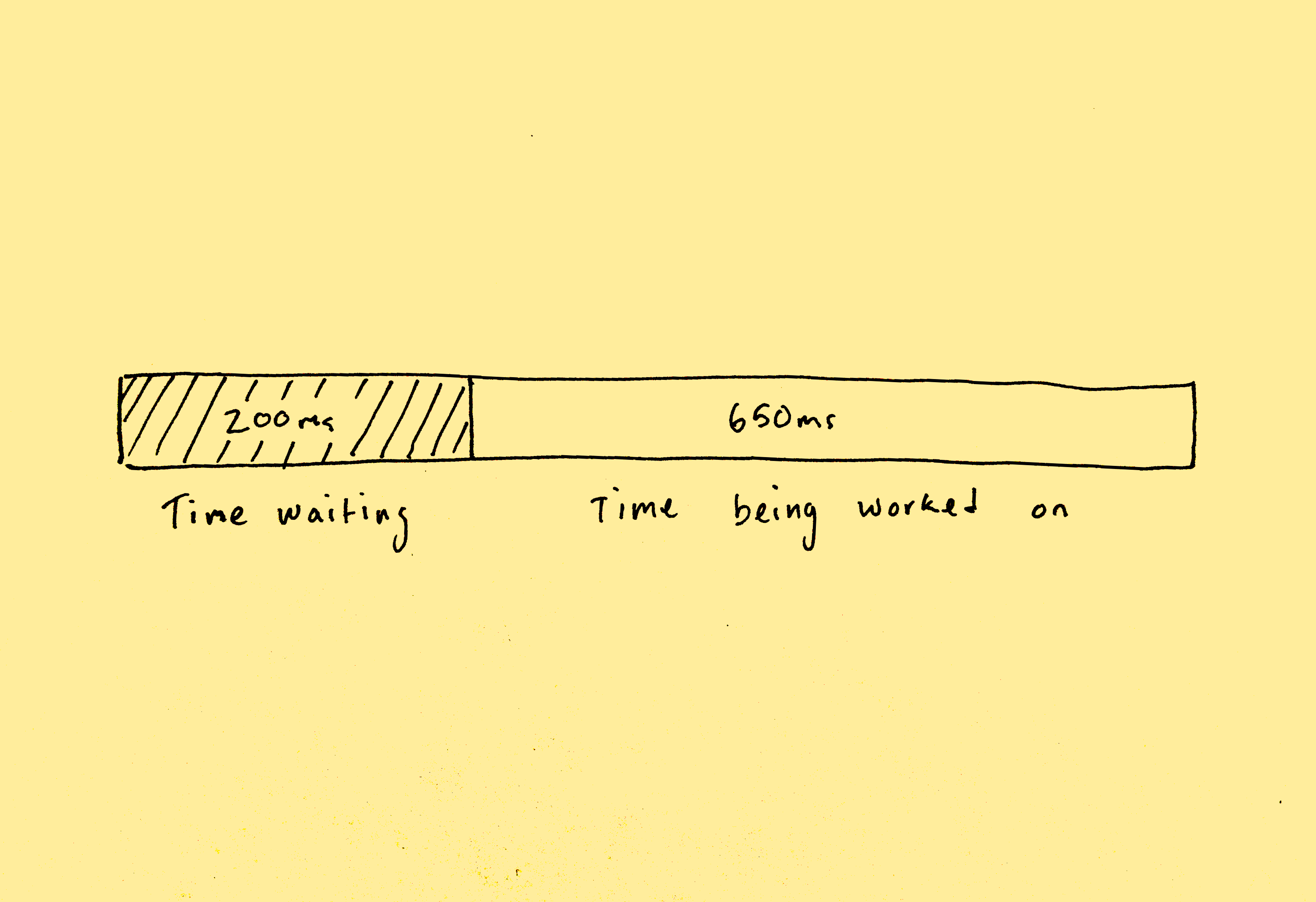
Because we are constantly adding new video effects and features to Runway, each of which may have different runtime and latency implications, we chose to focus on optimizing the "time work is waiting to be worked on" sub-problem. Our belief was that we might be able to decrease wait times for our streaming servers at the infrastructure level, instead of at the application level (the code which executes our individual video rendering effects). Any performance gains we achieve at the infrastructure level will decrease the latency of all effects, independent of how they are implemented.
Given this hypothesis, our challenge became: How do we distribute work to the workers as efficiently as possible, minimizing the time work is waiting to be worked on by a worker?
Distributing Work
In traditional web applications, HTTP requests are usually cheap. They deliver lightweight static content like text-based web pages, or they perform dynamic server-side rendering in a low-latency environment like loading data from a database or applying some basic templating to a file. HTTP load balancers have evolved over the years to solve these problems quite well.
However, our use of HTTP for the purpose of real-time video rendering and streaming deviates quite a bit from this norm. Our requests are very expensive. Depending on the video effect being rendered, one request could utilize dozens of CPU cores or be allocated access to an entire NVIDIA GPU for a period of several seconds. Nevertheless, we started with a simple approach...
Starting with HTTP Load Balancing
At Runway, we use Kubernetes to deploy and manage our compute-intensive services and an AWS Load Balancer in tandem with an NGINX Ingress Controller to route all inbound HTTP traffic to backend services running in our private cluster network. This is, and has always been, how most HTTP requests get routed to backend services running in our compute cluster.
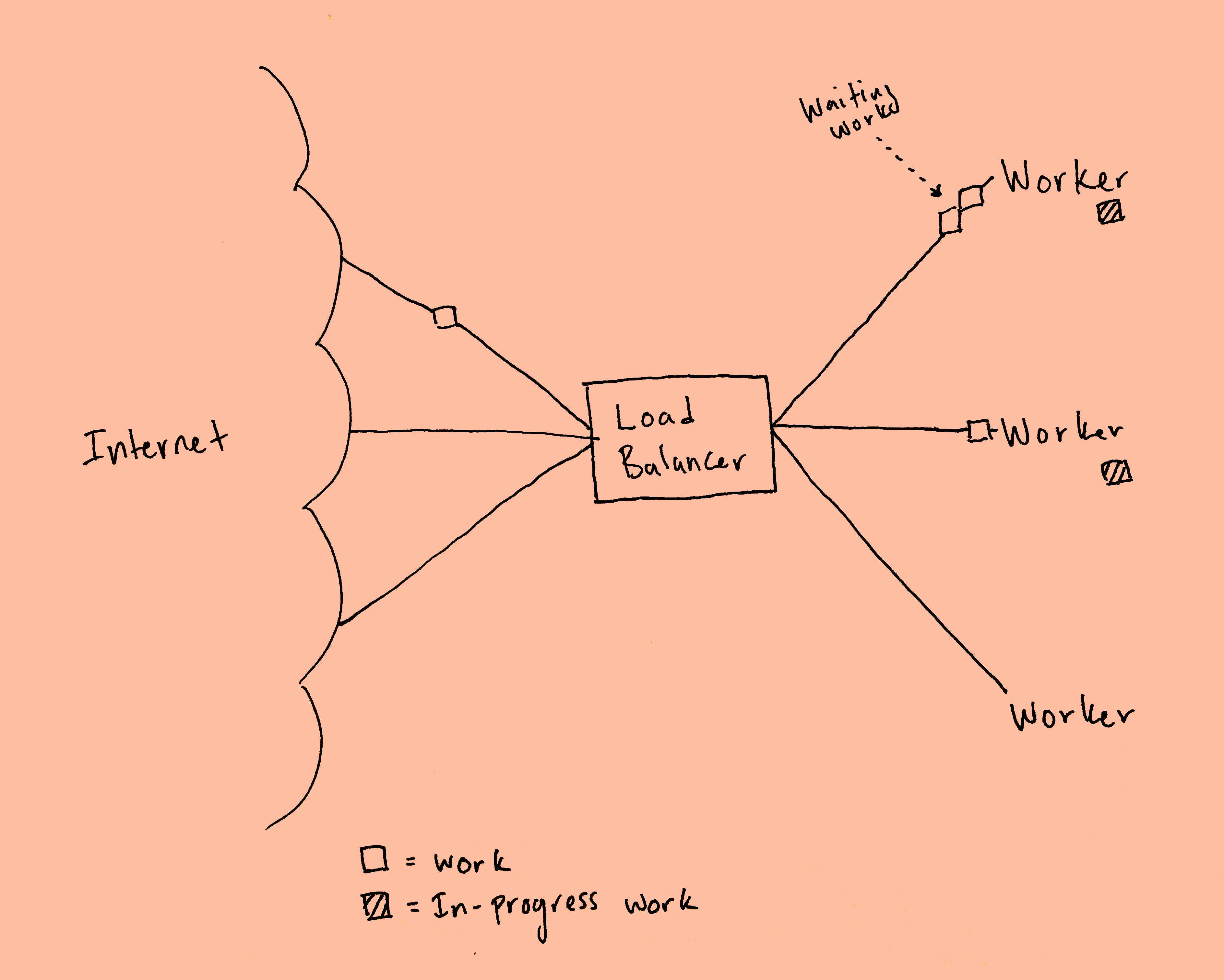
Aside from perhaps DNS-based load balancing, this is one of the most common methods of load balancing HTTP requests between a collection of clients and servers. It provides scalability and fault tolerance and refrains from overwhelming any single server with too many requests.
But as Runway’s user base increased, we started to notice high latency and request time variance. While HTTP load balancing did work for our use case, we couldn't help but wonder if there were better solutions out there.
As we thought more about how our HTTP environment was different than most, we suspected that work had a tendency to back up when multiple work units were assigned to a single worker. In this case, other workers could become idle but were unable to process waiting work that had already been assigned to another worker by the load balancer.
We set off to explore alternatives... 🛶
Migrating to Eager Worker Queues
The root of this problem stems from how the HTTP load balancer "pushes" new work onto workers as soon as it received it. During load spikes, multiple work items can be assigned to a single worker, which will work through them in the order they were assigned. This can lead to situations where some workers have been over-assigned work while other workers have been under-assigned work. In this scenario, idle workers are unable to process waiting work that has already been assigned to busy workers, either because it was assigned before the idle workers became available for work, or because these idle workers were recently added to the pool of workers. In short, we get waste.
By swapping a load balancer out for a work queue, we can invert the work assignment relationship. Eager workers can "pull" work as frequently as they are able to instead of having work "pushed" to them.
# A generic "eager worker"
while True:
work_item = get_item_from_input_queue()
result = perform_work(work_item)
send_result_to_output_queue(result)
Our hope was that this model of work distribution would increase the duty cycle of each worker, and therefore increase the throughput of our system as a whole.
We wanted a simple and quick way to test this theory without investing too much effort in refactoring code or introducing complexity. Because our streaming servers already operate as HTTP servers, and because we'd prefer to keep our changes isolated to the infrastructure level anyway, we set out to build a queueing system in front of our existing services.
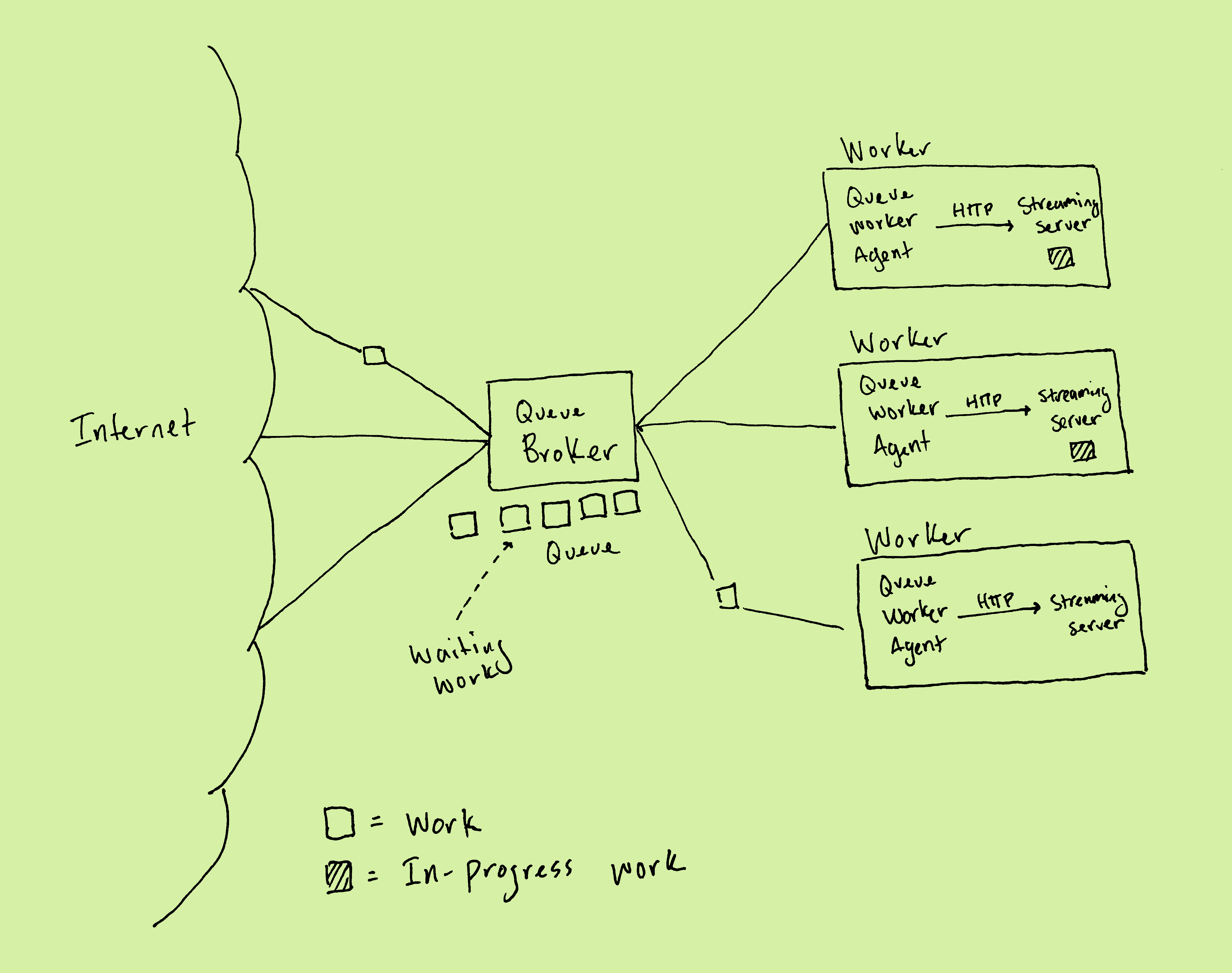
Our solution consists of two new architectural components: A queue broker which receives HTTP requests inbound from the browser and serializes them into a queue, and a collection of queue worker agents, one per streaming server. Each queue worker agent deserializes requests from the queue and executes them against its matching streaming server, sending the results back to the queue broker to return to the browser before immediately picking up new work from the input queue.
# Queue Broker
while True:
(req_id, date, method, url, body, headers) = get_inbound_request_from_browser()
work_item = (req_id, date, method, url, body, headers)
send_work_item_to_queue(work_item)
# ... Queue worker agent uses streaming server to perform work ...
result = wait_for_work_item_to_complete(req_id)
send_browser_response(result)
# Queue Worker Agent
while True:
work_item = get_work_item_from_queue()
result = perform_request_against_local_streaming_server(work_item)
notify_broker_work_is_complete(result)
Once this system was in place, we performed some load tests comparing this approach against our existing HTTP load balancing setup (our benchmark). We used Locust to test both work distribution methods against a variety of simulations. Each test varied:
- The number of concurrent users performing requests.
- The request patterns these simulated users exhibited (e.g. synchronously performing requests one after another, asynchronously performing requests randomly, asynchronously performing all requests instantaneously, etc.)
- The number of workers.
We ran these tests for several hours and compiled the results. Here’s a summary of some of the high-level takeaways.
- Response times between the benchmark and queue solutions were similar for the Synchronous tests. This aligned with our expectations, as the queue solution was only expected to outperform the benchmark during load spikes and when work is backed up.
- Response times were significantly lower for the queue solution over the benchmark solution for the asynchronous tests. Median response times were ~50% lower in three of the four tests and ~12% lower in the fourth. Maximum response times were lower in all cases, sometimes up to 3x as fast. The queue solution outperformed the benchmark more dramatically in the higher percentiles.
- In all tests with multiple users, the queue solution had less variance in request times.
- Failure rates were unchanged between the benchmark and the queue solutions.
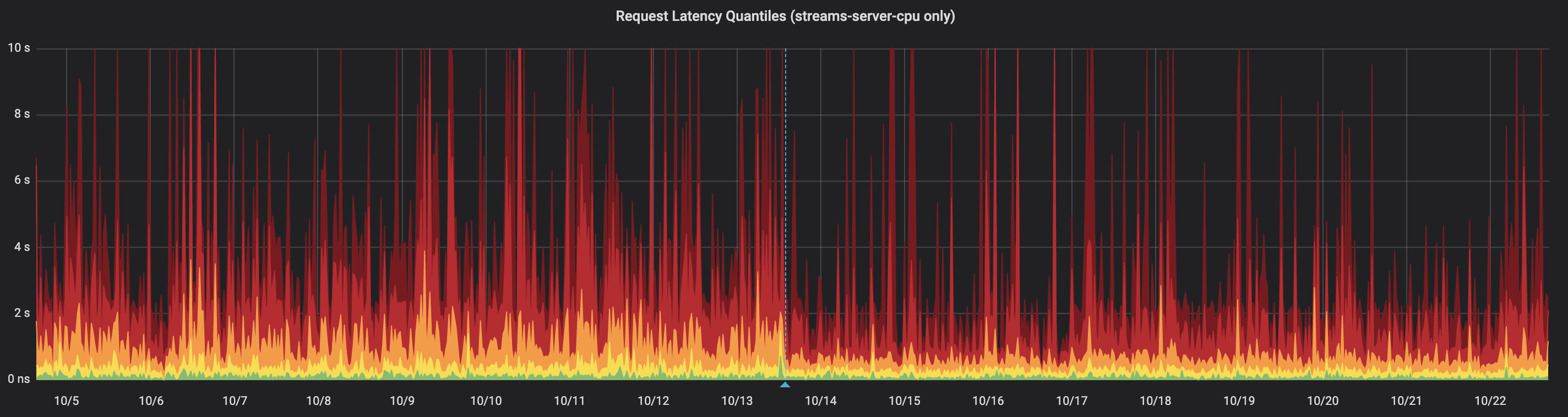
After shipping the changes to production, here's how the two approaches performed over a two-week period. The first seven days represent our baseline HTTP load balancing solution before we released the changes, and the last seven days represent our queue solution once the changes were released.
| HTTP Load Balancing (Baseline) | Eager Worker Queue |
|---|---|
| 95%ile: 4.06s 90%ile: 2.68s 75%ile: 1.22s 50%ile: 433ms 25%ile: 124ms |
95%ile: 2.94s (32% improvement) 90%ile: 1.68s (45% improvement) 75%ile: 699ms (54% improvement) 50%ile: 285ms (41% improvement) 25%ile: 80ms (43% improvement) |
As you can see, the queued worker solution significantly outperformed the basic HTTP load balancing method we had previously used to distribute work. As we’ll cover in an upcoming post, working with this queue-based architecture provides additional benefits related to autoscaling and performance monitoring as well. Stay tuned!
We're Just Getting Started
Spending engineering efforts on optimizations like these have helped us improve Runway for our existing users and lay the foundation we'll need to scale the product to support the next wave of users. We hope you've enjoyed reading about these engineering adventures as much as we've enjoyed exploring them. If this work sounds interesting to you, we're hiring. Come help us build the next generation of video editing tools on the web.